
半个月前我在 V2EX 上首发了我的开源项目 TalkWithGemini,一天内收到了不错的反响,非常感谢支持项目的朋友们。
之前的文章: [开源] Gemini Pro 极简聊天框架,支持图文聊天和语音对话模式 https://gemini.u14.app/
这半个月来 AI 届发生了两件大事,一件是 AI 届大佬 Openai 发布了令人惊叹的 GPT-4o 模型,而且也给免费用户开放了少量的访问次数。不得不说 GPT-4o 的发布会现场演示着实令人吃惊,感觉科幻电影中的 Her 马上就能出现在日常生活中。第二件事,自然是 Google I/O 2024 ,虽然 Google 一次性发布了很多与 AI 结合的新功能,比如无延迟的 AI 语音聊天 Gemini Live 、视频生成模型 Veo 、搜索集成 Gemini overview 、智能助理 Project Astra 。然而让我最在意的是 Google 开放了 100 万 Token 上下文的 Gemini 1.5 Pro 和更快的 Gemini 1.5 Flash 模型。这让我开发的 TalkWithGemini 有了全新的能力,能够理解文本文档、图片、音频以及视频文件!
Gemini 1.5 Flash 可以通过 ApiKey 免费使用,这个新模型支持 100 万 Token 的上下文,一天有 1500 次的使用额度,这让开发者有了极大的发挥空间。Gemini 1.5 Flash 响应速度很快,是 Gemini 1.5 Pro 的两倍,接近于 GPT-4o 。相对于 GPT-4o 而言,Gemini 1.5 Flash 可以说是一次超大杯的赠送。
通过几天熬夜开发及测试,我终于将 TalkWithGemini 升级到了多模态模式,这是一种质的飞跃。你可以在一次聊天过程中最多上传 3600 张图片或长达 9.5 小时的音频或 1 小时的视频,以及大量的文本内容。当然这些需要在你能正常使用 Google 服务的情况下才可以实现,而部署在 vercel 或 netlify 等平台上的项目,由于平台限制,无法上传大文件。
我测试了 Gemini 1.5 Flash 的视频理解能力,我拍了一段 10s 的短视频,他可以正确的描述整个视频片段的内容,并能够在后续提问中确认视频中某个事物出现的时间点,这跟 Project Astra 演示中点表现基本一致。而在图像测试中,Gemini 1.5 Flash 不愧是 Gemini 1.5 Pro 的 lite 版本,理解能力远高于之前的 Gemini Pro Vision 模型。
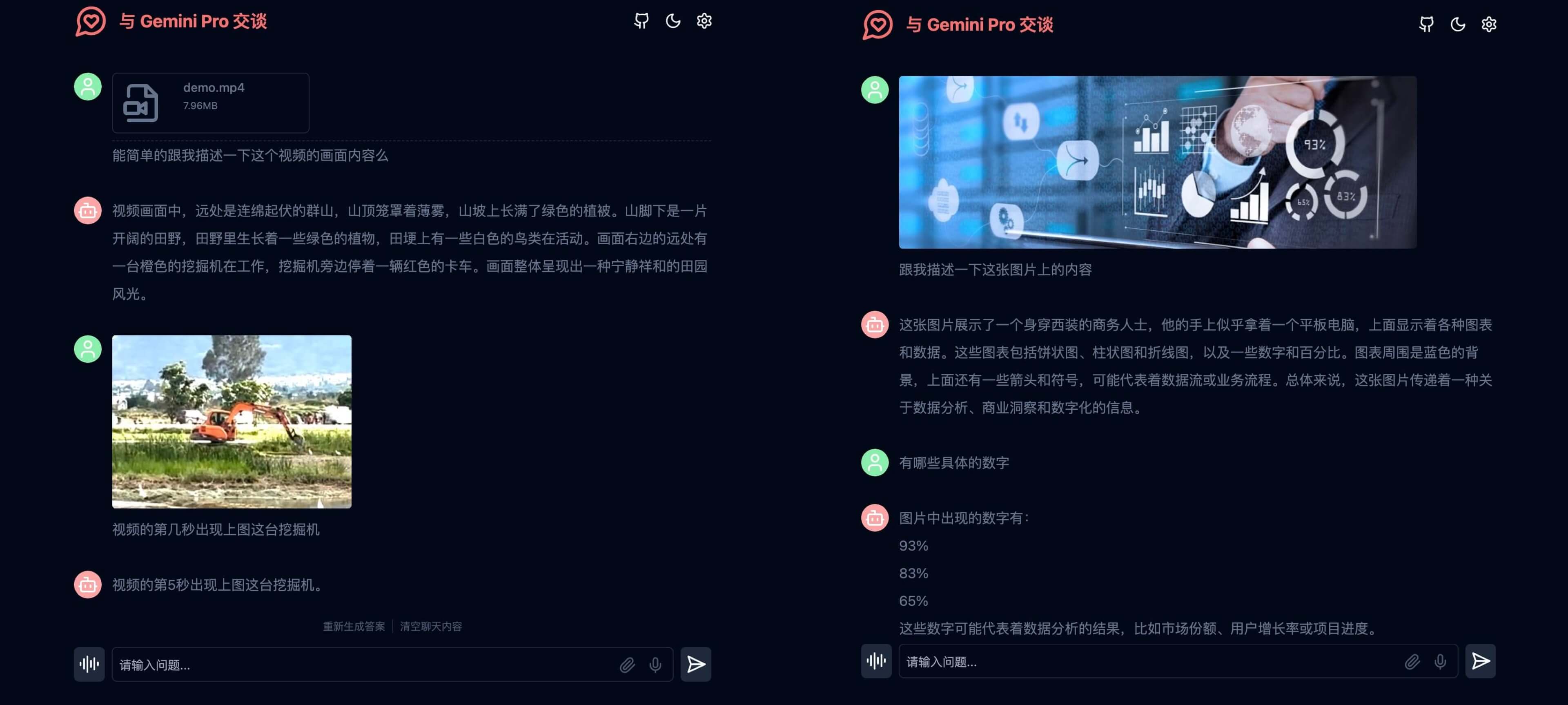
我还重构了话题广场,引入了 lobechat 的助理市场,让 Gemini 也能拥有数百个精选的系统指令。这可能是第一个无缝使用 Chatgpt 系统指令的项目。这得益于 Gemini 1.5 Pro 和 Gemini 1.5 Flash 新增的系统指令支持。
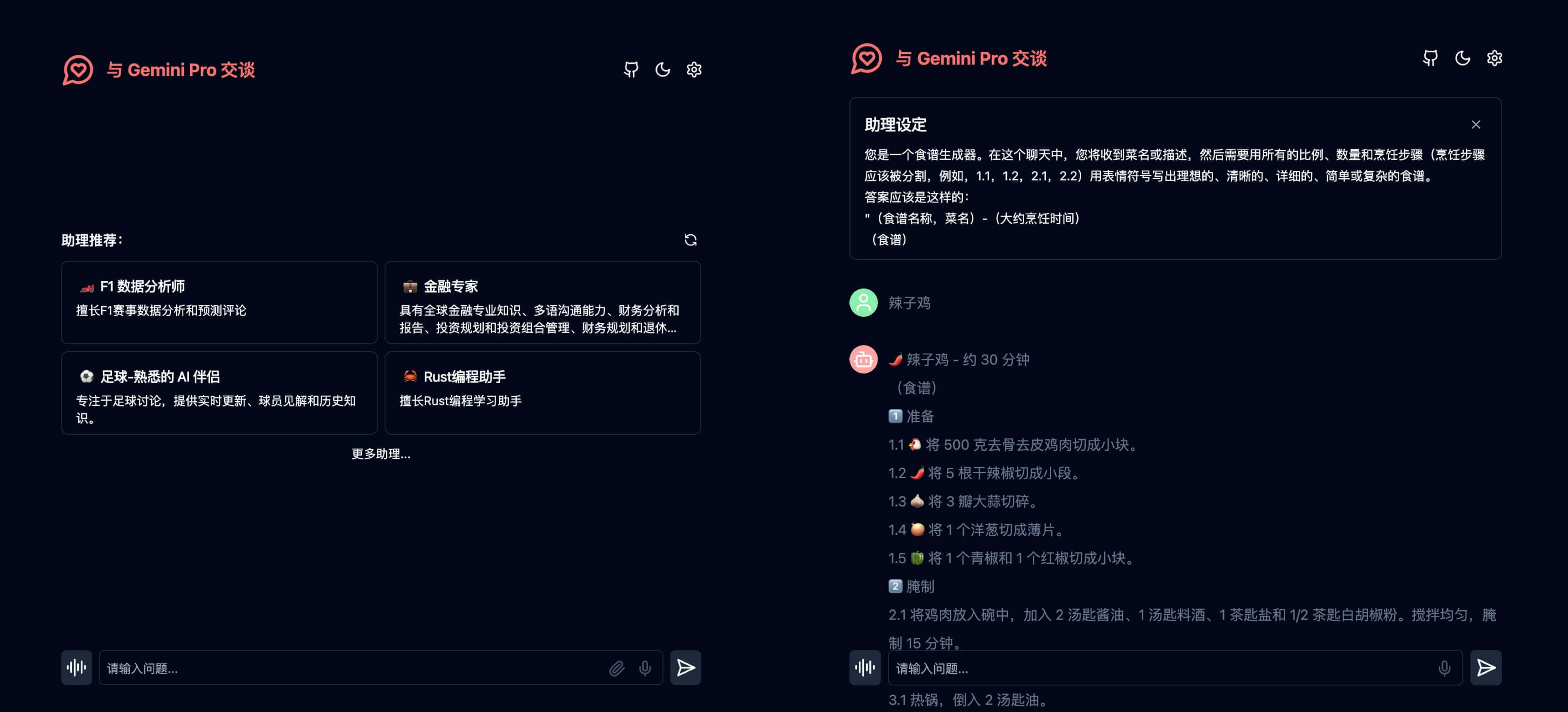
除了支持多模态模型和助理市场功能以外还做了以下大量更新:
- feat:添加系统指令支持
- feat:支持媒体文件作为提示内容
- feat:聊天 UI 支持附件,完成文件上传功能
- feat:添加了服务器端反向代理(实验性)
- feat:支持模型设置
- feat: 由于 0.9.3 版本以来数据存储结构发生变化,增加数据迁移功能
- refactor:重构主题广场,引入助理市场
- refactor:重构助理推荐功能
- refactor:重构设置面板,优化小屏幕上的页面布局
- refactor:消息列表使用官方数据格式
- refactor:优化错误信息的显示逻辑
- refactor:优化视觉模型和文本模型的处理逻辑
- refactor:使用 localforage 替换 localStorage 实现
- refactor:在某些无法使用对话模式的浏览器中隐藏功能模块
- refactor:优化访问密码处理逻辑
- doc:更新 README 文档,添加一些常见问题及解决方案,并添加更多功能截图
- doc:添加 Cloudflare Worker 创建指南
- fix:修复语音合成初始化参数设置错误的问题
- fix:修复部分场景下重新生成答案无法生效的问题
- chore:部分页面组件改为延迟加载,提高首页加载速度。
你现在可以通过 https://gemini.u14.app/ 进行体验。
注意:该项目部署在 vercel 上,如果使用服务端 api ,上传文件大小将受到限制(无法上传超过 5MB 的文件),建议自建服务或者通过 api key ,使用本地代理或接口代理访问。
项目地址:https://github.com/Amery2010/TalkWithGemini
希望能得到更多人的支持( star ),你们的支持是我项目开发的最大动力!
第 1 条附言 · 13 天前
目前 star 数超过了 200 ,虽然不及预期,但还是很感谢各位对支持哈,对于部分朋友在 issues 里提到的一些需求,后续为会择优进行实现。
第 2 条附言 · 11 天前
https://gemini.u14.app/ 的访问密码是 TalkWithGemini ,在之前的帖子里有公布,但在这个帖子里忘记写上了,到不部分用户无法体验,是我的疏忽。
18 条回复 • 2024-05-27 17:15:14 +08:00
 |
1
cyio 13 天前
1. 仓库项目名无法通过 vercel 名称校验,改成 - 连接解决
2. flash 提示是文本模型,不能识别图片 3. 建议输出加个朗读按钮 |
 |
2
amery2010 OP @cyio vercel 名称无法通过校验的问题,我这边之前没能注意,后续会做调整。
Flash 模型需要通过附件上传图片,如果附件图片没能完成上传就发送信息,可能会出现你目前的情况,即图片未能作为对话的一部分发送。 朗读按钮的问题之前一直有在犹豫要不要在,因为有一个对话模式存在,因此不确定是否有用户希望在聊天界面朗读文本,后续会做考虑。 |
 |
3
biubiuyy 13 天前
在线地址报错,我的 key 是正常的
400: [GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:streamGenerateContent?alt=sse: [400 ] User location is not supported for the API use. |
|
4
amery2010 OP @biubiuyy 你用的 VPN 或者 vercel 后端走的路线不再 Gemini API 目前支持的国家范围内。这个问题可以在 GitHub 仓库最后的常见问题中可以找到解决方案,可以通过部署代理进行解决。
|
 |
5
bestkayle 13 天前
不能在 vercel 管理后台设置访问密码和 key 吗,目前用 vercel 部署的好像不能设置访问密码,输入框是 disabled
|
 |
7
SGRRYRS 12 天前
部署试用了下,UI 好看,而且解决了 Next-web 在预设的这些 Prompt 上的问题(Next-web 那叫 Mask ?基本没什么人用),这个放在首页就很好嘛,简单明了。BTW ,我还是没办法使用语音交互,视频上传也是没有成功,也已自建了 cf 的中转,可能有其他浏览器上的问题?待测试。感谢你的辛勤工作!
|
|
8
bestkayle 12 天前
不知道为啥,之前的 key 不但可以用 1.5flash 还能直接用 1.5pro
|
|
12
amery2010 OP @SGRRYRS 语音交互可以参考 GitHub 仓库最后的常见问题部分,如果你的浏览器不支持浏览器语音识别接口或者无法正常访问浏览器自带的语音识别接口( chrome 浏览器是需要网络正常访问 Google 网站)。这个问题因浏览器差异很大。视频上传的问题你可以看一下浏览器 console 面板是否报错,如果未正常上传,应该会有错误提示。
|
|
13
amery2010 OP @SGRRYRS 我今天在开发过程中可能复现了你的问题,我遇到的问题是浏览器在发送请求时由于 CORS 问题导致请求发送失败,这个在使用代理 api 时需要注意中转服务器是否允许跨域请求。我为这个项目写了一个专门的 worker ,在 GitHub 仓库最后的常见问题部分可以找到链接
|
 |
14
GotKiCry 11 天前
@biubiuyy 代理到不支持的地区就会这样,看下代理规则 generativelanguage.googleapis.com 是怎么走的
|
|
15
SGRRYRS 9 天前
@amery2010 #13 嘿嘿😜,我就是用的你写的那个。就是不知道为什么只能上传非常小的视频文件,差不多 1M 左右的可以正常,几十兆的就失败了,说 Payload 过大。我是部署在 Vercel 上的,是哪里出了什么问题吗
 |
|
16
amery2010 OP @SGRRYRS vercel 和 netfily 两个平台 edge 环境的文件的上传大小分别限定为 4.5MB 和 4MB ,这个是平台限制。
下周一我会发布新版本,通过几天的努力,新版本在 vercel 平台上已经支持大文件上传了。 当前版本你可以参考常见问题中的解决方案,利用 cf worker 代理来上传大文件 |
|
17
SGRRYRS 7 天前
@amery2010 #16 我又来啦
同步了你今天的更新嘿嘿😜,视频上传也正常了,就是发现个之前的错误,为什么设置里的模型代理地址不会随着环境变量更改呢,还是谷歌的,我手动改成自建的就可以了,是我哪里没操作对吗 https://raw.githubusercontent.com/guozhigq/emoji_storage/main/coolapk/coolapk_emotion_26_kelian.png 对了,感谢大佬的辛勤付出! |