
这是一个创建于 2247 天前的主题,其中的信息可能已经有所发展或是发生改变。
背景
朋友工作总要找资料什么的,大多是 pdf 扫描版格式,无法复制,需要转成 word 或者文字,但由于其人穷,又不买那些 pdf 在线转换 word 的工具。得知后,帮助开发一个工具给她使用。
支持功能
- image ocr
node test/ocr.test.js(图片文字提取) - converting scanned PDF's to an image (扫描版 PDF 转为图片后文字提取,同下)
- support pdf ocr
node test/pdf.test.js( PDF 文字提取) - support electron desktop packager ( Electron 打包为 Desktop App )
Demo 截图
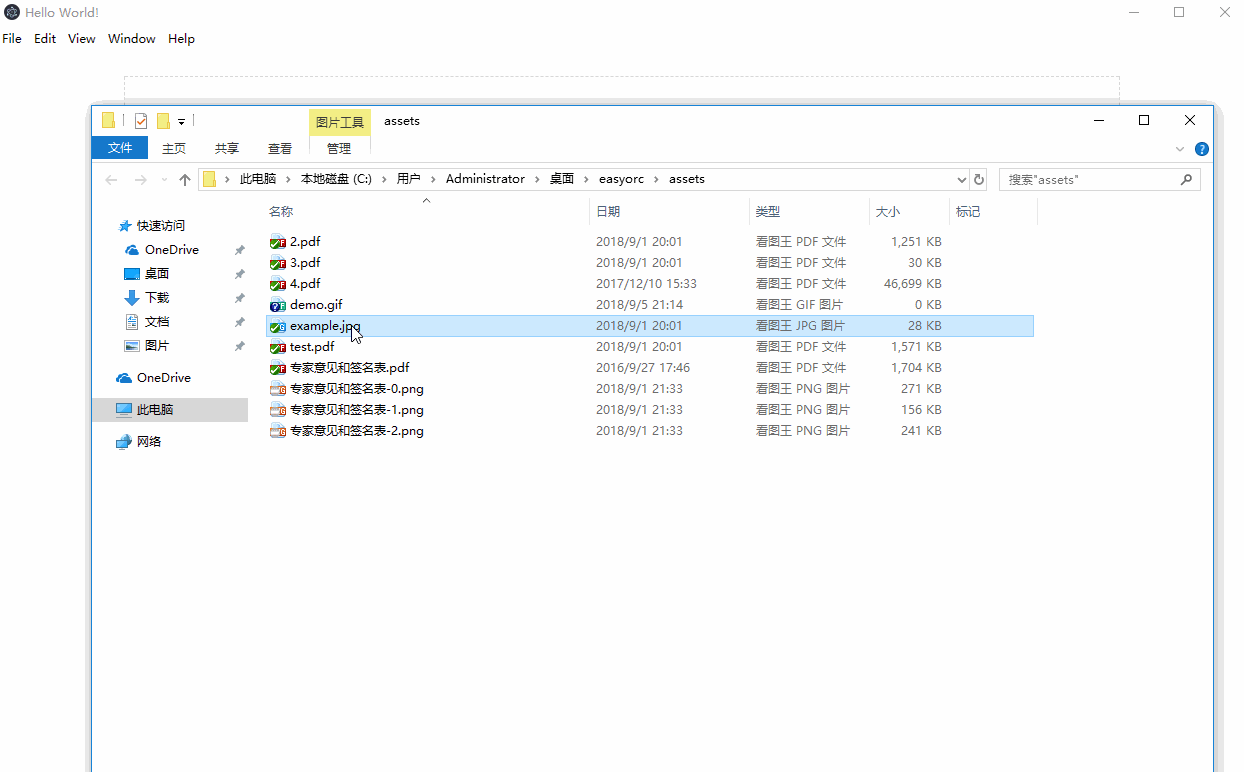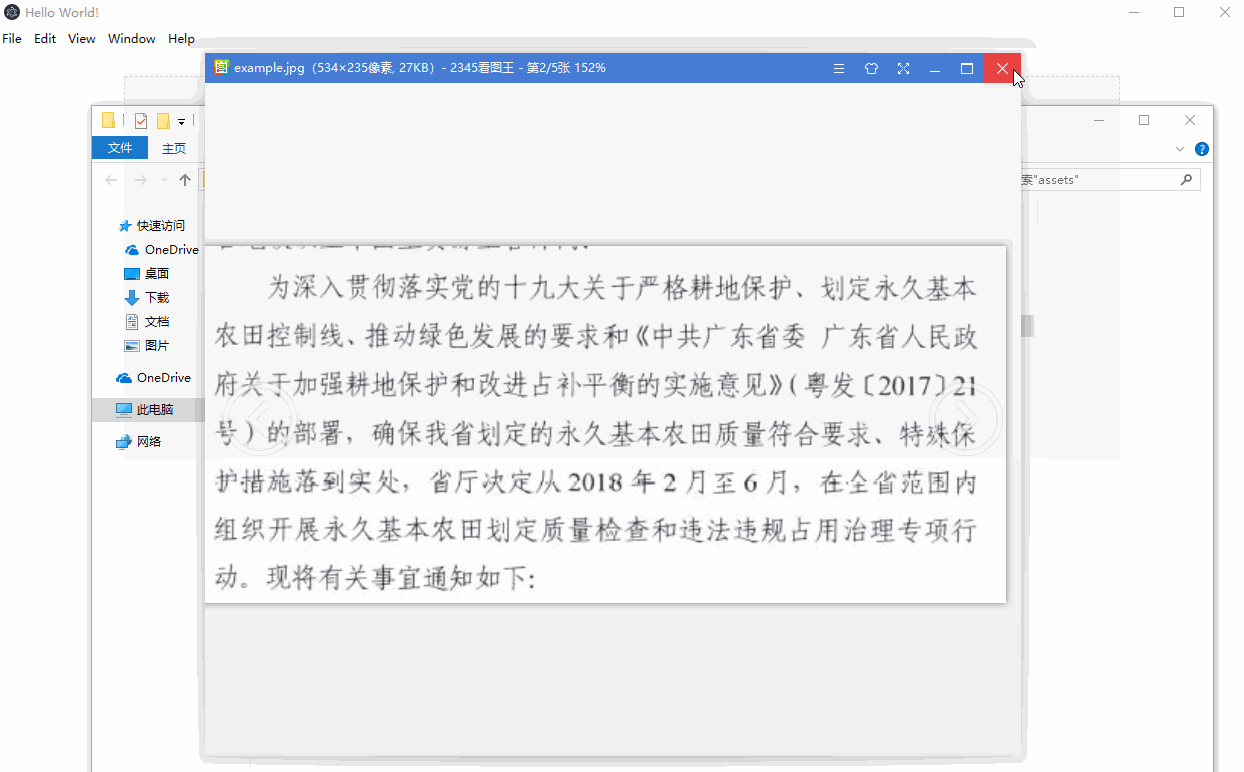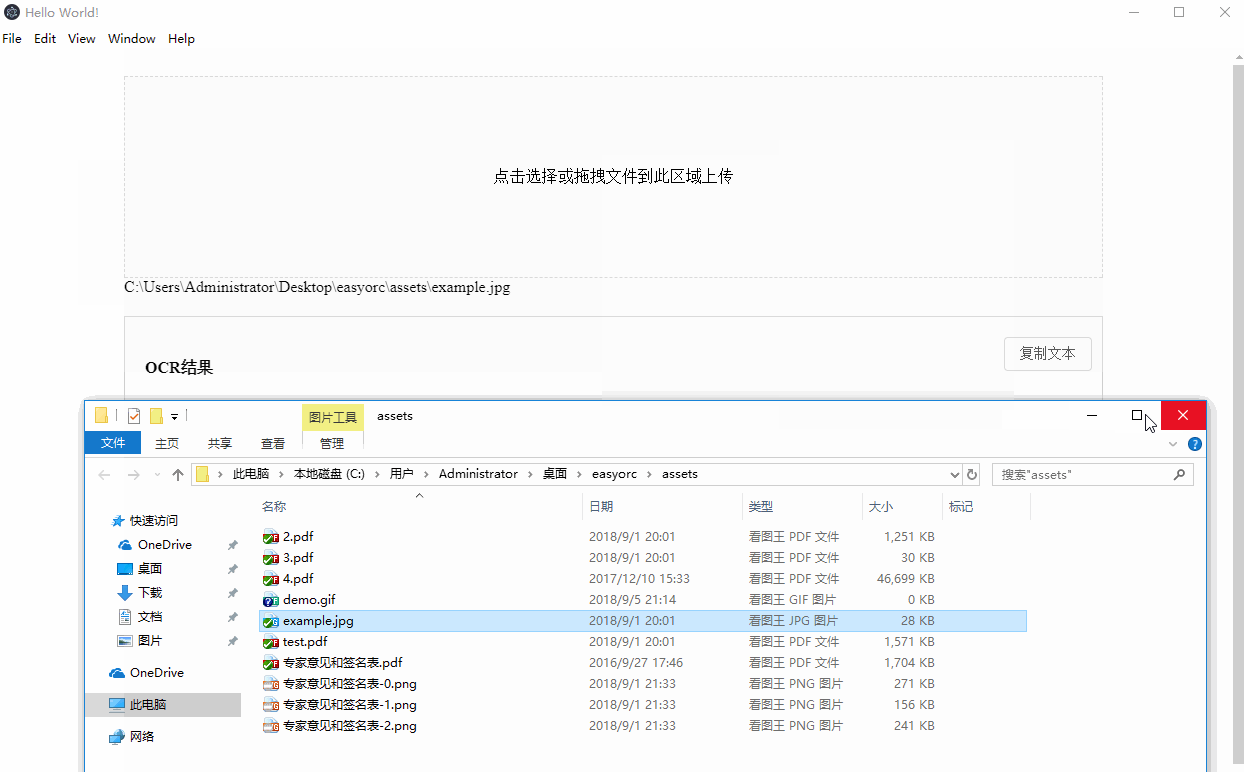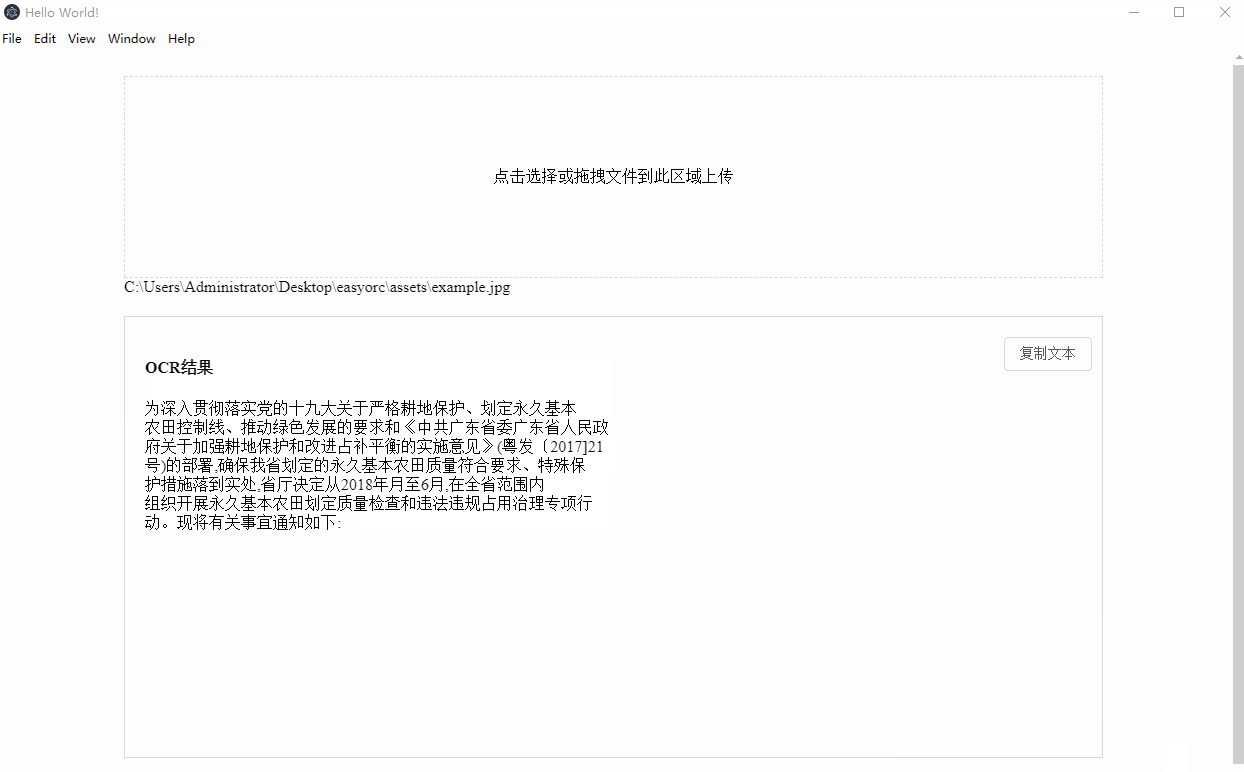

实现过程介绍
本项目基于百度 AIP 平台,OCR 接口
图片 OCR 提取文字
这个简单,直接走百度 OCR 即可得到结果。node.js 调用 SDK 而已
正常格式 PDF
这个通过pdfinfo 工具 + GraphicsMagick 来实现,pdfinfo 获取 pdf 文件信息(分页信息等),GraphicsMagick 将 pdf 作为图片(处理图片很强大)。
扫描版 PDF
这个麻烦是在 pdfinfo 工具是无法获取 pdf 文件信息的,需要代码做兼容情况处理。扫描版 PDF 最终还是转换图片后再 OCR 提取文字。
源码
详细使用方式阅读README.md
https://github.com/giscafer/easyocr
欢迎━(`∀´)ノ亻!学习交流
第 1 条附言 · 2018-09-07 09:51:43 +08:00
欢迎 PR 一起开发强大的 OCR 工具
 |
1
lucky2javascript 2018-09-07 01:22:44 +08:00
能说下原理吗?草体字能识别不
|
 |
2
sean10 2018-09-07 01:34:03 +08:00 via Android
@leeseeanchiu 原理作者也说了,调的百度 OCR 的 SDK,百度有支持草体识别的话,就能识别
|
 |
3
scmod 2018-09-07 08:25:22 +08:00
楼主是直接购买了那个识别服务吗?我记得免费有个试用上限来着.
|
 |
4
giscafer OP @scmod 我用的是免费版,
|
|
5
giscafer OP |
 |
6
jimmy2010 2018-09-07 11:09:16 +08:00
感谢,恰好能用到。
|
 |
8
nicolasleohu 2018-10-08 15:04:30 +08:00
赞啊~准确率能达到多少?
|
|
9
giscafer OP @nicolasleohu 准确率依赖百度 OCR 接口,我用的是基础免费版的,高精准的每天次数不多。
没有公式和代码等图片的识别准确率达到 99%以上。 |
|
10
nicolasleohu 2018-10-23 11:01:33 +08:00
@giscafer 噢噢,了解了
|