
[MIT 开源]: PDF Craft 一个更懂技术的开源 PDF 转换工具
BlackHole1 ·PRO
大家好,最近我们团队开源了个项目,和大家分享一下。
我们平时看技术文档或者学术论文,PDF 是绕不开的坎。但目前的 PDF 转换工具,总有那么几个让人抓狂的点:
- 扫描版的 PDF,转出来基本就是一堆乱码,没法看。
- 数学公式,特别是 LaTeX ,转完成 Word 或者 Markdown 后,格式全错,还不如截图。
- 排版,双栏的、图文混排的,一转换就面目全非。
- 很多工具背后都是调 LLM API ,不仅花钱,速度和稳定性也看缘分。
为了解决这些的问题,我们基于 DeepSeek-OCR 重写了一个转换引擎:pdf-craft。
效果预览
有什么不一样?
我们没打算做一个大而全的工具,而是把精力都放在了技术细节上,希望能做到:
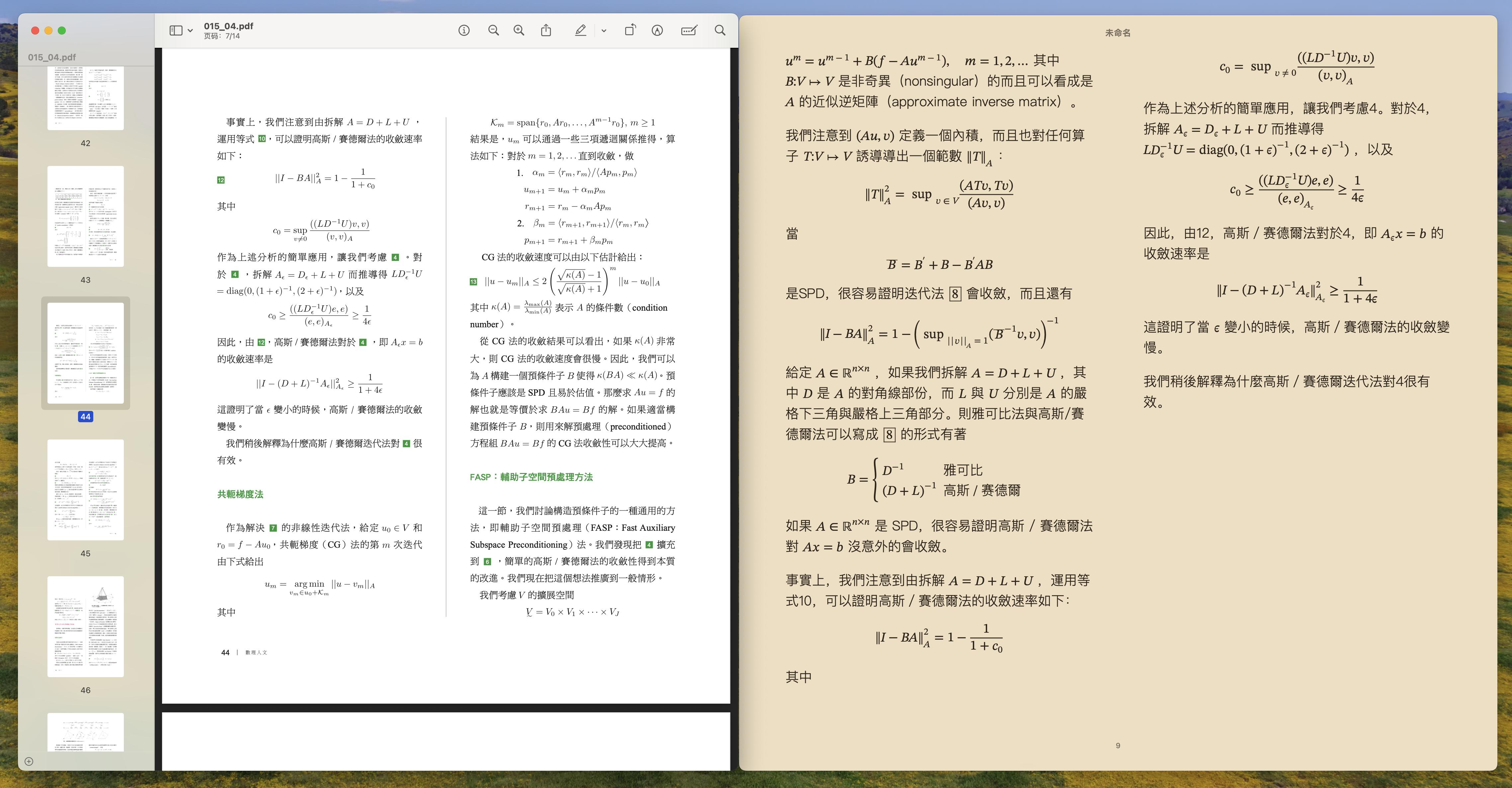
- 更好的 OCR 识别:既然使用了 DeepSeek-OCR ,文档结构理解、表格、公式、图片这些复杂场景的识别准确率,我们很有信心。
- 更智能的布局还原:特别优化了双栏和图文混排,目标是转成 Markdown 或 EPUB 后,还能有接近纸质书的阅读体验。
- 更完美的 LaTeX 公式支持:无论是行内公式还是独立公式,都能精准识别并还原,这点我们花了不少功夫。
- 更灵活的输出:目前支持 Markdown 和 EPUB ,目录、注释这些也都会自动生成。
怎么用?
我们提供了两种方式:
1. 本地免费跑(我们最推荐的)
如果你有一张还不错的显卡( RTX 3060 或以上),可以尝试根据 README.md 中的步骤在本地运行。
完全免费,不限次数,数据都在你自己的电脑上。
当然,pdf-craft 引擎本身是完全开源的( MIT 协议),你可以直接 clone 仓库回来自己开发及部署。
2. 云服务
没算力的朋友也不用担心,我们同时提供了在线的云服务。没有订阅费,按实际用量计费,新用户注册会送一些免费额度,可以先体验一下。
关于开源
我们相信,一个好的工具应该是开放和透明的。特别是文档处理这种场景,谁也不希望自己的文件被泄露。
开源,意味着:
- 你可以审查代码,知道它到底是怎么工作的。
- 可以自己部署,数据安全掌握在自己手里。
- 可以定制功能,缺什么就自己动手。
- 当然,也欢迎你贡献代码,一起让它变得更好。
最后
这个项目还在快速迭代,肯定有不少问题。欢迎大家来我们的 GitHub 仓库提 Issue 和 PR 。
- 在线体验:https://pdf.oomol.com
- GitHub 仓库:oomol-lab/pdf-craft
- API 文档:https://pdf.oomol.com/api
表格将在本周进行支持
目前尚无回复