
Python 源码漫游指南(一)
作者:北京秘塔科技算法研究员 Qian Wan
前几天 IEEE Spectrum 发布了第五届顶级语言交互排行榜,Python 语言继续稳坐第一把交椅,并且相比去年的排行情况,拉开了与第二名的距离(去年第二名的排名得分为 99.7 )。从下图能看出 Python 的优势还是很明显的,而且在 Web、企业级和嵌入式这三种应用类别的流行度都很高。

冰冻三尺非一日之寒。Python 语言自 1990 年由 Guido van Rossum 第一次发布至今已经快三十年的历史,它支持多种操作系统,并以 CPython 为参考实现。Python 语言在很多领域都有杀手级的应用框架,如深度学习方面有 PyTorch 和 Tensorflow,自然语言处理有 NLTK,Web 框架有 Django、Flask,科学计算有 Numpy、Scipy,计算机视觉有 OpenCV,科学绘图有 Matplotlib,爬虫有 Scrapy,凡此种种,不一而足。面对这么多不同种类的 Python 应用框架,下面一些问题是值得我们思考的:
- 怎样使用 Python 语言能将程序的性能发挥到极致?
- 什么类型的单一语言框架不适合用 Python 来实现?
- 多语言框架中与 Python 语言的交互如何做到高效?
- 从架构的角度看,Python 内部的架构设计如何?
- 从使用 Python 语言的角度,它适合于什么样的软件架构设计?
- 在多语言( Python 与 CUDA )、异构节点( CPU 与 GPU )、多业务类型( IO 密集型与 CPU 密集型)以及跨区域(跨国多机房)的复杂系统中,Python 语言的定位又如何?其他语言呢?
三言两语可能很难比较全面的回答上面一些问题,而且只研究 Python 语言得到的答案也可能会有失偏颇。但是 Python 语言的源代码能够为回答这些问题提供一些线索,而且通过阅读源码能让我们在使用 Python 语言时看到一些以前我们看不到的细节,就如同《黑客帝国》电影里的 Neo 一样能看到母体世界的源代码,也能像 Neo 那样在机器的世界里飞天遁地。
Python 环境的部署
我们使用 pyenv 花几分钟时间来构建 Python 运行环境,它不仅可以与操作系统原生的 Python 环境隔离,还能支持多种版本的 Python 环境,另外也支持在同一 Python 版本下的多个虚拟环境,可以用来隔离不同应用的 Python 依赖包。部署代码如下
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
$ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
$ git clone https://github.com/pyenv/pyenv-virtualenv.git ${HOME}/.pyenv/plugins/pyenv-virtualenv
$ echo 'eval "$(pyenv init -)"' >> ~/.bashrc
$ echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.bashrc
$ CONFIGURE_OPTS=--enable-shared $HOME/.pyenv/bin/pyenv install 3.6.6 -k -v
$ $HOME/.pyenv/bin/pyenv virtualenv 3.6.6 py3.6
部署好了之后每次运行下面命令就能替换掉系统原生的 Python 环境
$ pyenv activate py3.6
安装后的目录结构如下
- Python 源码:
~/.pyenv/sources/3.6.6/Python-3.6.6 - 头文件:
~/.pyenv/versions/3.6.6/include/python3.6m/ - 动态链接库:
~/.pyenv/versions/3.6.6/lib/libpython3.6m.dylib
目录结构
要深入剖析 Python 的源代码,就要对源码中几个大的模块的作用有一个初步的认识。我们进入到源码目录~/.pyenv/sources/3.6.6/Python-3.6.6,其中几个跟 Python 语言直接相关的目录及其功能如下
Include:C 头文件,与部署好的头文件目录~/.pyenv/versions/3.6.6/include/python3.6m/中的文件一致(严格来说,部署好的头文件目录中会多一个自动生成的pyconfig.h文件),这些头文件定义了 Python 语言的底层抽象结构。Lib:Python 语言库,这部分不参与 Python 的编译,而是用 Python 语言写好的模块库。Modules:用 C 语言实现的 Python 内置库。Objects:Python内置对象的 C 语言实现以及抽象接口的实现。Parser:Python 编译器的前端,词法分析器和语法分析器。后者就是基于龙书的 LL(1)实现的。Programs:可执行文件~/.pyenv/versions/3.6.6/bin/python的源码所在的目录。Python:Python 虚拟机所在的目录,也是整个 Python 语言较为核心的部分。
使用下面的图示能更好的展示这些目录之前的相互关系,虚线箭头表示提供接口定义,实线箭头表示提供服务,自顶向下的结构也体现了语言设计在架构上的层次关系。
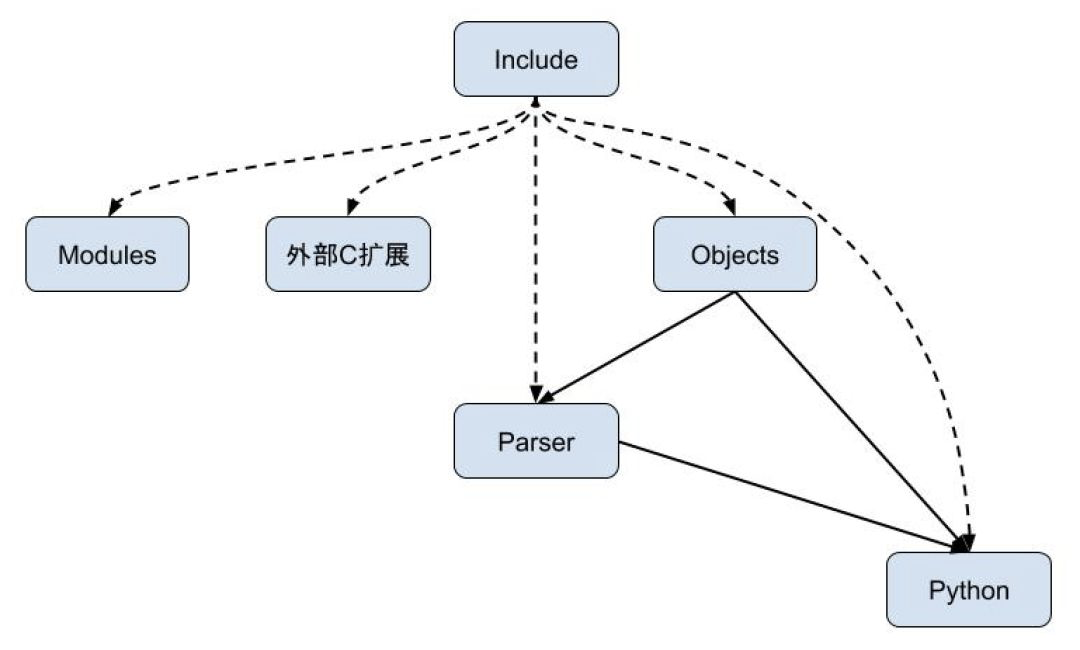
Include目录
从上面这些模块的大致功能上分析,我们可以判断出Include、Objects和Python中的代码比较重要。我们先看一下这三个目录包含的代码量
$ cat Include/* Objects/* Python/* | wc -l
cat: Objects/clinic: Is a directory
cat: Objects/stringlib: Is a directory
cat: Python/clinic: Is a directory
215478
21 万行代码的阅读量有点略大,我们还是先挨个看看这些目录中文件的命名、大小以及一些注释,看能不能得到一些线索。
$ wc -l Include/*.h | sort -k1
...
324 pystate.h
370 objimpl.h
499 dynamic_annotations.h
503 pyerrors.h
637 Python-ast.h
767 pyport.h
1077 object.h
1377 abstract.h
2342 unicodeobject.h
15980 total
从文件名和文件大小可以初步判断object.h和abstract.h是两个比较重要的头文件,实际上它们定义了 Python 底层的抽象对象以及统一的抽象接口。
unicodeobject.h虽然体积大,但是有很多跟它类似的头文件,如boolobject.h、longobject.h、floatobject.h等等,这些头文件应该是内置类型的头文件,我们可以暂时不去理会这些文件,对语言的总体理解不会造成困难。
为了不漏掉一些重要的头文件,我们快速阅读一下其他头文件中可能包含的一些引导性的注释,发现这些头文件也比较重要:
Python.h:元头文件,通常在写 Python 的 C 扩展时会包含它。ceval.h:作为Python/ceval.c的头文件,而Python/ceval.c负责运行编译后的代码。code.h:包含字节码相关的底层抽象。compile.h:抽象语法树的编译接口。objimpl.h:跟内存相关的抽象对象高层接口,如内存分配,初始化,垃圾回收等等。pystate.h:线程状态与解释器状态以及它们的接口。pythonrun.h:Python 代码的语法分析与执行接口。 通过以上筛选,我们看看还剩下多少代码:
$ cat object.h abstract.h objimpl.h Python.h ceval.h code.h compile.h pystate.h pythonrun.h | wc -l
3950
核心头文件压缩到不到 4 千行。
Objects目录
用类似的思路,我们能从Objects目录中筛选出一些比较重要的文件
abstract.c:抽象对象的接口实现。codeobject.c:字节码对象的实现。object.c:通用对象操作的实现。obmalloc.c:内存分配相关实现。typeobject.c:Type对象实现。 统计一下代码量
$ wc -l abstract.c codeobject.c object.c obmalloc.c typeobject.c
3246 abstract.c
921 codeobject.c
2048 object.c
2376 obmalloc.c
7612 typeobject.c
16203 total
一下子新增了 1.6 万行,毕竟是实打实的 C 语言实现。
另外还有一些具象化的对象实现文件,虽然它们跟longobject.c和dictobject.c之类的对象实现类似,都是具体的对象,但是它们跟 Python 语言特性比较相关,在这里也把它们列出来,做为备份。
classobject.c:类对象实现。codeobject.c:代码对象实现。frameobject.c:Frame 对象实现。funcobject.c:函数对象实现。methodobject.c:方法对象实现。moduleobject.c:模块对象实现。 顺便统计下行数
$ wc -l classobject.c codeobject.c frameobject.c funcobject.c methodobject.c moduleobject.c
648 classobject.c
921 codeobject.c
1038 frameobject.c
1031 funcobject.c
553 methodobject.c
802 moduleobject.c
4993 total
Objects目录中合计约 2.1 万行。通过探索这些源代码,我们看出 Python 的一个设计原则就是:一切皆对象。
严格来说,只有 Python 语言暴露给外部使用的部分才抽象成了对象,而一些仅在内部使用的数据结构则没有对象封装,如后面会提到的解释器状态和线程状态等。
Python目录
依然经过一轮筛选,能得到下面这些比较重要的文件
ast.c:将具体语法树转换成抽象语法树,主要函数是PyAST_FromNode()ceval.c:执行编译后的字节码。ceval_gil.h:全局解释器锁( Global Interpreter Lock,GIL )的接口。compile.c:将抽象语法树编译成 Python 字节码。pylifecycle.c:Python 解释器的顶层代码,包括解释器的初始化以及退出。pystate.c:线程状态与解释器状态,以及它们的接口实现。pythonrun.c:Python 解释器的顶层代码,包括解释器的初始化以及退出。 能够注意到,pylifecycle.c和pythonrun.c的功能是类似的,实际上查阅 Python 开发历史记录能发现前者是因为开发需要从后者分离出来的。统计一下代码的数量:
$ wc -l ast.c ceval.c ceval_gil.h compile.c pystate.c pythonrun.c
5277 ast.c
5600 ceval.c
270 ceval_gil.h
5329 compile.c
958 pystate.c
1596 pythonrun.c
19030 total
这样浓缩下来Include、Objects和Python三个文件夹中比较重要的代码一共大约 4.4 万行,先不说我们这样筛选出来的一波有没有漏掉重要信息,其他很多支持性的代码都还没有包含进去。至少目前有了一个大的轮廓,接下来在深入代码的时候可以慢慢扩展开。
顶层调用树
前面讨论了 Python 源码的主要目录结构,以及其中主要的源文件。这里我们换一个思路,看看一个 Python 源文件是如何在 Python 解释器里面运行的。调用 Python 的可执行文件~/.pyenv/versions/3.6.6/bin/python和调用我们编写的其他 C 语言程序在方式上并没有太大区别,不同之处在于 Python 可执行文件读取的 Python 源文件,并执行其中的代码。Python 之于 C 就如同 C 之于汇编,只是 Python 编译的字节码在 Python 虚拟机上运行,汇编代码直接在物理机上运行(严格来说还需要转换成机器代码)。
以下面这条 Python 源文件运行为例来考察 Python 可执行文件的执行过程(大家可以玩玩这个生命游戏,运气好能看到滑翔机)。
$ python ~/.pyenv/sources/3.6.6/Python-3.6.6/Tools/demo/life.py
既然 Python 的可执行文件是 C 语言编译成的,那么一定有 C 语言的入口函数main,它就位于 Python 源码的./Programs/python.c文件中。
int
main(int argc, char **argv)
{
// ...
res = Py_Main(argc, argv_copy);
// ...
}
顺藤摸瓜,我们可以梳理出调用树的主干部分。下面的树形结构中,冒号左边为函数名,右边表示函数定义所在的 C 源文件,树形结构表示函数定义中包含的其他函数嵌套调用。
main: Programs/python.c
└─ Py_Main: Modules/main.c
├─ Py_Initialize: Python/pylifecycle.c
│ ├─ PyInterpreterState_New: Python/pystate.c
│ ├─ PyThreadState_New: Python/pystate.c
│ ├─ _PyGILState_Init: Python/pystate.c
│ └─ _Py_ReadyTypes: Objects/object.c
├─ run_file: Modules/main.c
│ └─ PyRun_FileExFlags: Python/pythonrun.c
│ ├─ PyParser_ASTFromFileObject: Python/pythonrun.c
│ │ ├─ PyParser_ParseFileObject: Parser/parsetok.c
│ │ └─ PyAST_FromNodeObject: Python/ast.c
│ └─ run_mod: Python/pythonrun.c
│ ├─ PyAST_CompileObject: Python/compile.c
│ └─ PyEval_EvalCode: Python/ceval.c
│ ├─ PyFrame_New: Objects/frameobject.c
│ └─ PyEval_EvalFrameEx: Python/ceval.c
└─ Py_FinalizeEx: Python/pylifecycle.c
不得不说,Python 源码的可读性非常好,这些函数的命名方式都是自解释的。Python 源文件的运行大致分为两个步骤:
Py_Initialize:初始化过程,主要涉及到解释器状态、线程状态、全局解释器锁以及内置类型的初始化。run_file:运行源文件,可以分为三个小步骤PyParser_ASTFromFileObject:对源文件的文本进行语法分析,得到抽象语法树。PyAST_CompileObject:将抽象语法树编译成PyCodeObject对象。PyEval_EvalCode:在 Python 虚拟机中运行PyCodeObject对象。
Py_FinalizeEx:源文件执行结束后的清理工作。
用流程图的形式表示上述调用树的主干部分应该更加清晰明了。
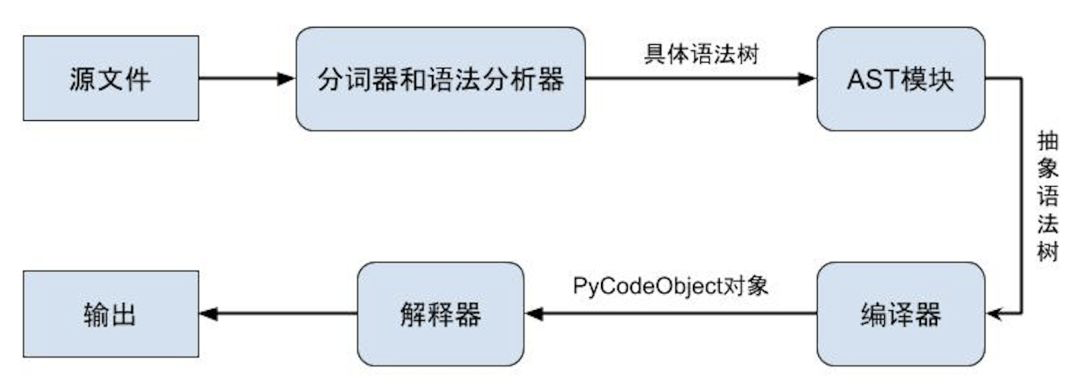
需要指出的是,解释器循环真正执行的是PyEval_EvalFrameEx函数,它的参数是PyFrameObject对象,该对象为PyCodeObject对象提供了执行的上下文环境,所以PyFrameObject和PyCodeObject都是非常核心的对象。Python 提供了一些工具让我们可以查看编译后的代码对象,即对编译好的函数进行反汇编。下面的例子虽然简单,但已经能给人清晰的直观认识
>>> from dis import dis
>>> class C(object):
... def __init__(self, x):
... self.x = x
... def add(self, y):
... return self.x + y
...
>>> dis(C)
Disassembly of __init__:
3 0 LOAD_FAST 1 (x)
2 LOAD_FAST 0 (self)
4 STORE_ATTR 0 (x)
6 LOAD_CONST 0 (None)
8 RETURN_VALUE
Disassembly of add:
5 0 LOAD_FAST 0 (self)
2 LOAD_ATTR 0 (x)
4 LOAD_FAST 1 (y)
6 BINARY_ADD
8 RETURN_VALUE
反编译的结果是一系列的操作码。头文件Include/opcode.h包含了 Python 虚拟机的所有操作码。能看出上面simple_tuple和simple_list这两个函数反编译后的最大区别么?tuple是作为常量被加载进来的,而list的生成还需要调用BUILD_LIST。原因在于tuple在 Python 的运行时会进行缓存,也就是每次使用无需请求操作系统内核以获得内存空间。对比一下使用tuple和list的耗时情况
>>> %timeit x = (1, 2, 3)
10.9 ns ± 0.0617 ns per loop (mean ± std. dev. of 7 runs, 100000000 loops each)
>>> %timeit x = [1, 2, 3]
46.5 ns ± 0.186 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
从统计结果能看出,tuple的在效率上的优势非常明显。如果某一段调用特别频繁的代码中有些list可以替换成tuple,千万不要犹豫。
总结
我们可以试着为文章开头第一个问题提供一些思路。我们知道,对计算机做任何形式上的抽象都有可能伤害到计算的效率,对于 Python 来说有以下几点
- Python 对象的内存部署方式是以在满足一定效率的前提下足够通用为目标的,因此在面临特定问题时它不一定是最优的。
- Python 是动态类型语言,并不是编译型语言,导致代码在运行时是可变的,从 Python 将抽象语法树和
PyCodeObject对象暴露出来这一点就能看出。 - 全局解释器锁也会妨碍使用多进程来实现性能的提升。
- Python 虚拟机作为对 CPU 硬件的抽象也是没法甩锅的。
所以为了提高 Python 程序的效率,我们需要深入了解 Python 对象的实现原理、
PyCodeObject的特性以及全局解释器和 Python 虚拟机的限制。之于文章开头的其他问题,我们将随着 Python 源码的深入研究慢慢展开。
现在我们对 Python 代码的运行有了一个宏观的理解,而且大量的细节都有待深入研究。通过对调用树主干部分的梳理,能看出其他比较重要的支持性模块还包括 Python 抽象对象PyObject,抽象语法树及其编译,PyCodeObject对象,PyFrameObject对象,解释器状态,线程状态,全局解释器锁。在以后的文章中,我们会分别对这些模块进行探讨。

