
这是一个创建于 1682 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow 看大厂图数据库技术实践。
{kind=link}
[作者介绍]
- 戚名钰:快手安全-移动安全组,主要负责快手安全情报平台的建设
- 倪雯:快手数据平台-分布式存储组,主要负责快手图数据库的建设
- 姚靖怡:快手数据平台-分布式存储组,主要负责快手图数据库的建设
[公司简介]
快手是一家全球领先的内容社区和社交平台,旨在通过短视频的方式帮助人们发现所需、发挥所长,持续提升每个人独特的幸福感。
一. 为什么需要图数据库
传统的关系型数据库,在处理复杂数据关系运算上表现很差,随着数据量和深度的增加,关系型数据库无法在有效的时间内计算出结果。
所以,为了更好的体现数据间的连接,企业需要一种将关系信息存储为实体、灵活拓展数据模型的数据库技术,这项技术就是图数据库( Graph Database )。
相比于传统关系型数据库,图数据库具有以下两个优点:
第一点,图数据库能很好地体现数据之间的关联关系
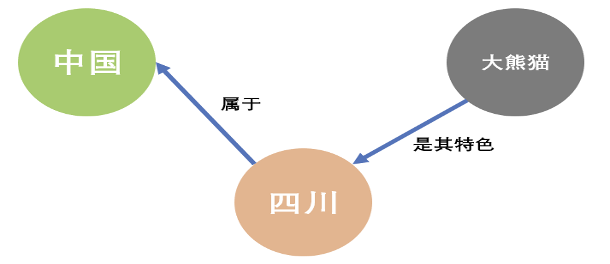
从上面的图模型可以看出,图数据库的目标就是基于图模型以一种直观的方式来展示这些关系,其基于事物关系的模型表达,使图数据库天然具有可解释性。
第二点,图数据库能很好地处理数据之间的关联关系:
- 高性能:传统关系型数据库在处理关联关系数据时主要靠 JOIN 操作,而随着数据量的增多和关联深度的增加,受制于多表连接与外键约束,传统关系型数据库会导致较大的额外开销,产生严重的性能问题。而图数据库从底层适配了图模型的数据结构,使得它的数据查询与分析速度更快。
- 灵活:图数据库有非常灵活的数据模型,使用者可以根据业务变化随时调整图数据结构模型,可以任意添加或删除顶点、边,扩充或者缩小图模型等,这种频繁的数据 schema 更改在图数据库上能到很好的支持。
- 敏捷:图数据库的图模型非常直观,支持测试驱动开发模式,每次构建时可进行功能测试和性能测试,符合当今最流行的敏捷开发需求,对于提高生产和交付效率也有一定帮助。
基于以上两个优点,图数据库在金融反欺诈、公安刑侦、社交网络、知识图谱、数据血缘、IT 资产及运维、威胁情报等领域有巨大需求。
而快手安全情报则是通过整合移动端、PC Web 端、云端、联盟及小程序等全链条的安全数据,最终形成统一的基础安全能力赋能公司业务。
由于安全情报本身具有数据实体多样性、关联关系复杂性、数据标签丰富性等特点,因此采用图数据库来做是最为合适的。
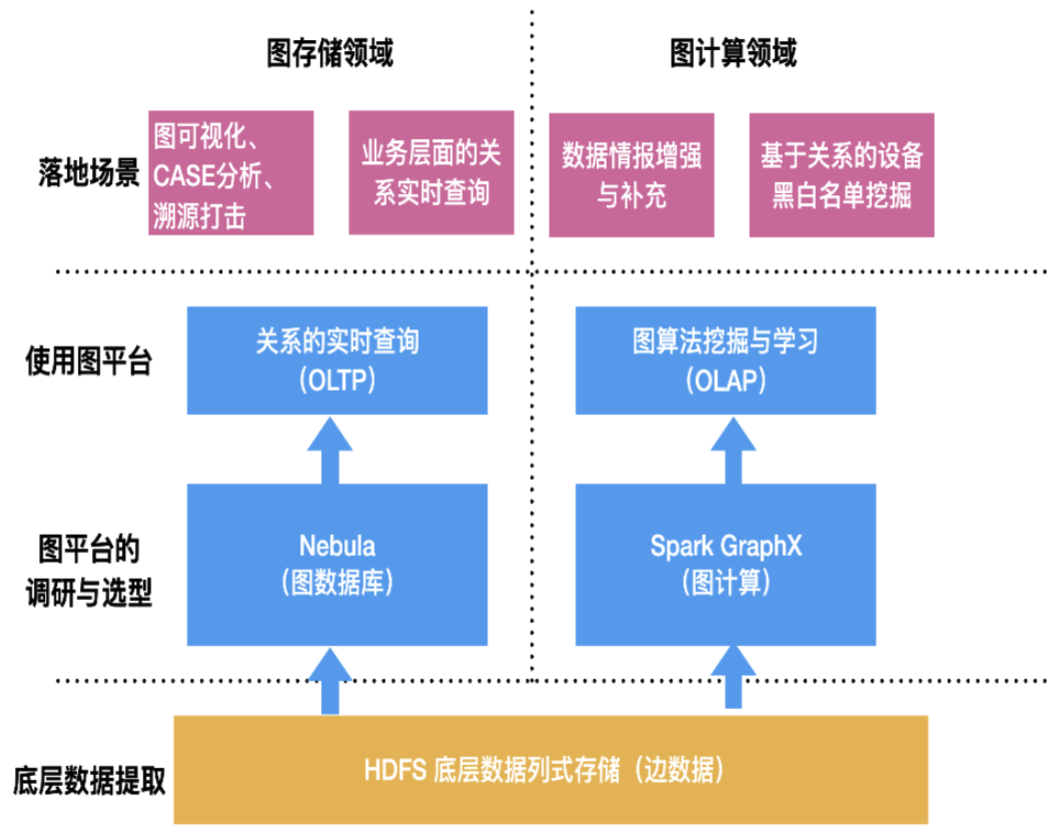
二. 为什么选择 Nebula Graph
通过收集需求及前期调研,快手安全情报在图数据库上最终选择了Nebula Graph作为生产环境的图数据库。
2.1 需求收集
对于图数据库的选型来说,其主要需求是在数据写入与数据查询两个方面:
-
数据写入方式:离线 + 在线
- 需要支持天级的离线数据批量导入,每天新增写入数据量在百亿级别,要求当天产生的关联关系数据,小时级能写完
- 需要支持数据的实时写入,Flink 从 Kafka 中消费数据,并在做完逻辑处理之后,直接对接图数据库,进行数据的实时写入,需要支持的 QPS 在 10W 量级
-
数据查询方式:毫秒级的在线实时查询,需要支持的 QPS 在 5W 量级
- 点及边的属性过滤及查询
- 多度关联关系的查询
-
部分基本图数据分析能力
- 图最短路径算法等
综上所述,此次选型的适用于大数据架构的图数据库主要需要提供 3 种基本能力:实时和离线数据写入、在线图数据基本查询、基于图数据库的简单 OLAP 分析,其对应定位是:在线、高并发、低时延 OLTP 类图查询服务及简单 OLAP 类图查询能力。
2.2 选型
基于以上的确定性需求,在进行图数据库的选型上,我们主要考虑了以下几点:
- 图数据库所能支持的数据量必须要足够大,因为企业级的图数据经常会达到百亿甚至千亿级别
- 集群可线性拓展,因为需要能够在生产环境不停服的情况下在线扩展机器
- 查询性能要达到毫秒级,因为需要满足在线服务的性能要求,且随着图数据量的增多,查询性能不受影响
- 能够较方便的与 HDFS 、Spark 等大数据平台打通,后期能够在此基础上搭建图计算平台
2.3 Nebula Graph 的特点
- 高性能:提供毫秒级读写
- 可扩展:可水平扩容,支持超大规模图存储
- 引擎架构:存储与计算分离
- 图数据模型:点( vertex )、边( edge ),并且支持点或边的属性( properties )建模
- 查询语言:nGQL,类 SQL 的查询语言,易学易用,满足复杂业务需求
- 提供了较为丰富和完善的数据导入导出工具
- Nebula Graph 作为开源图数据库产品,在开源社区具有良好的活跃度
- 相较于 JanusGraph 和 HugeGraph,Nebula Graph 查询性能有极大的提升
正是基于Nebula Graph的以上特点以及对我们使用场景和需求的恰好满足,因此最终选择Nebula Graph作为我们生产环境的图数据库来使用。
三. 安全情报的图数据建模
如下图所示,从情报的角度来看,安全的分层对抗与防守,从下到上,其对抗难度是逐渐增加的:
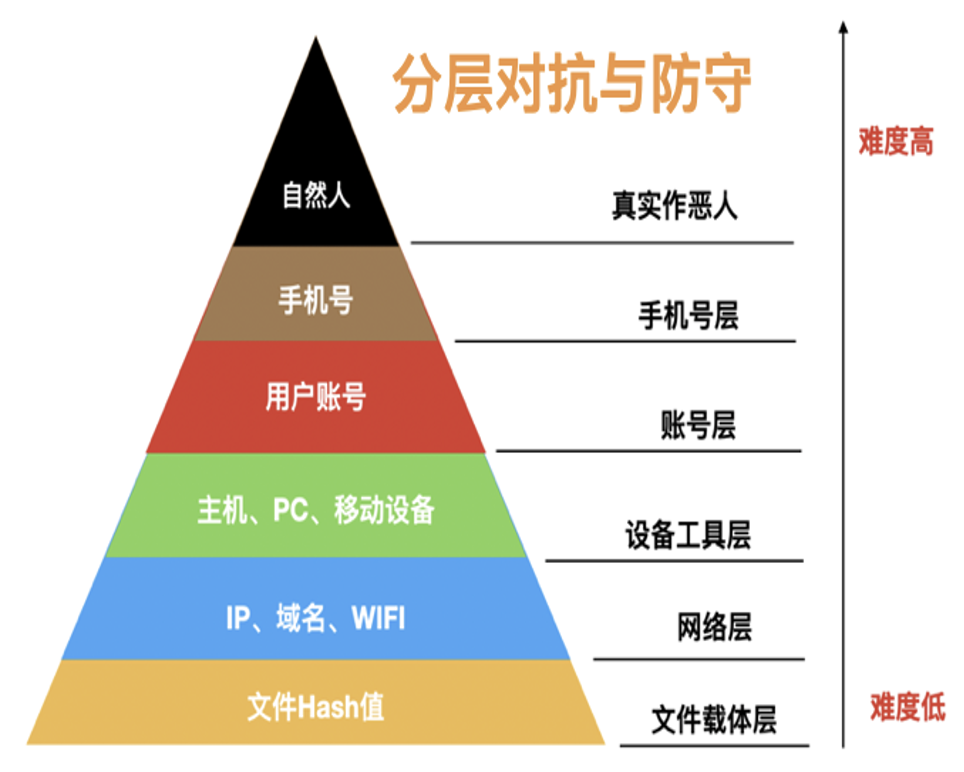
每一个平面上,之前攻击方与防守方都是单独的对抗,现在利用图数据库之后,可以将每一个层次的实体 ID 通过关联关系串联起来,形成一张立体层次的网,通过这张立体层次的网能够使企业快速掌握攻击者的攻击方式、作弊工具、团伙特征等较全貌的信息。
因此基于安全数据的图结构数据建模,可以将原来的平面识别层次变成立体网状识别层次,能帮助企业更清晰准确的识别攻击与风险。
3.1 基本图结构
安全情报的图建模主要目的是希望判断任何一个维度风险的时候,不单单局限于该维度本身的状态与属性去看它的风险,而是将维度从个体扩展为网络层面,通过图结构的数据关系,通过上下层次(异构图)及同级层次(同构图)立体去观察该维度的风险。
以设备风险举例:对一个设备而言,整体分为网络层、设备层、账号层和用户层这四个层面,每个层面都由其代表性的实体 ID 来表达。通过图数据库,可以做到对一个设备进行立体的三维层次的风险认知,这对于风险的识别会非常有帮助。
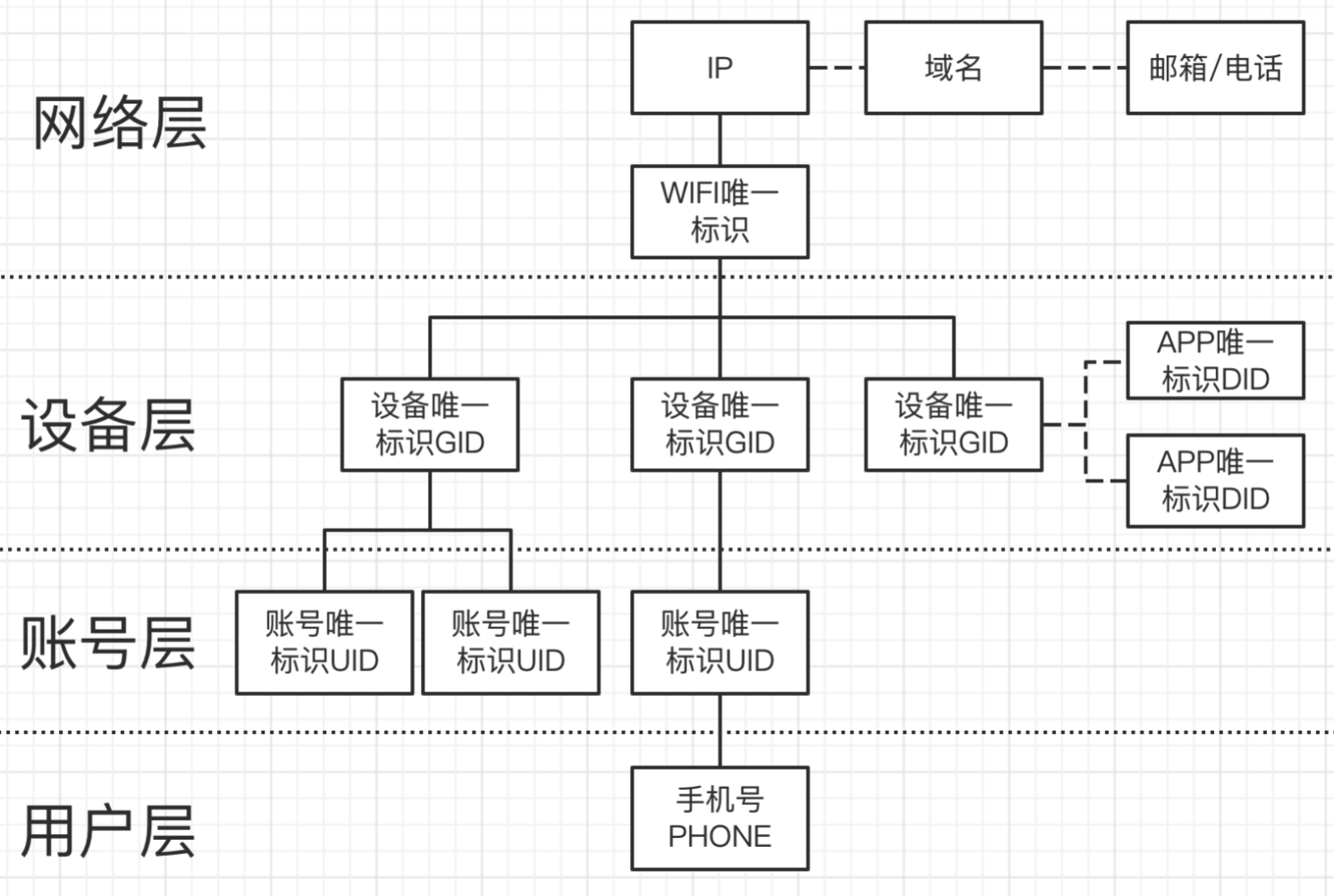
如上图所示,这是安全情报的基本图结构建模,以上构成了一个基于安全情报的知识图谱。
3.2 动态图结构
在基本图结构之上,还需要考虑的是,每一种关联关系的存在都是有时效性的,A 时间段内关联关系存在,B 时间段内该关联关系则未必存在,因此我们希望安全情报能在图数据库上真实反映客观现实的这种不同时间段内的关联关系。
这意味着需要随着查询时间区间的不同,而呈现出不同的图结构模型的数据,我们称之为动态图结构。
在动态图结构的设计上,涉及到的一个问题是:在被查询的区间上,什么样的边关系应该被返回?
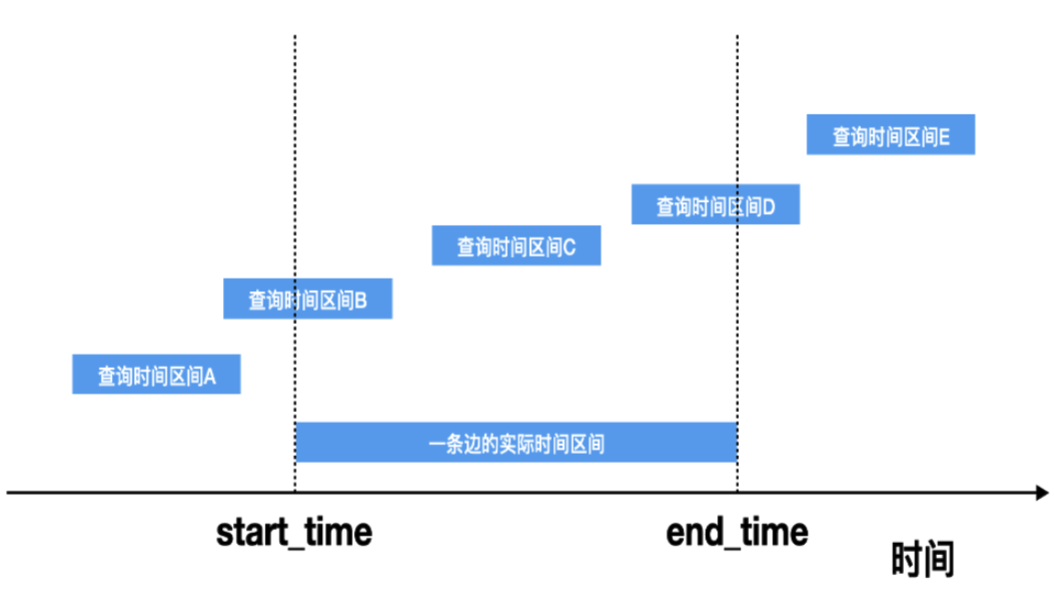
如上图所示,当查询时间区间为 B 、C 、D 时,这条边应该要被返回,当查询时间区间为 A 、E 时,这条边不应该被返回。
3.3 权重图结构
在面对黑灰产或者真人作恶时,往往会出现这种情况:就是一个设备上面会对应非常多的账号,有些账号是不法坏人自己的常用账号,而有些账号则是他们买来做特定不法直播的账号。为配合公安或法务的打击,我们需要从这批账号里面精准区分出哪些账号是真实坏人自己的常用账号,而哪些账号只是他们买来用于作恶的账号。
因此这里面会涉及到账号与设备关联关系边的权重问题:如果是该设备常用的账号,那么表明这个账号与这个设备的关系是较强的关系,则这条边的权重就会高;如果仅仅是作恶 /开直播的时候才会使用的账号,那么账号与设备的关系则会比较弱,相应权重就会低一些。
因此我们在边的属性上,除了有时间维度外,还增加了权重维度。
综上所述,最终在安全情报上所建立的图模型是:带权重的动态时区图结构。
四. 基于图数据库的安全情报服务架构与优化
整体安全情报服务架构图如下所示:
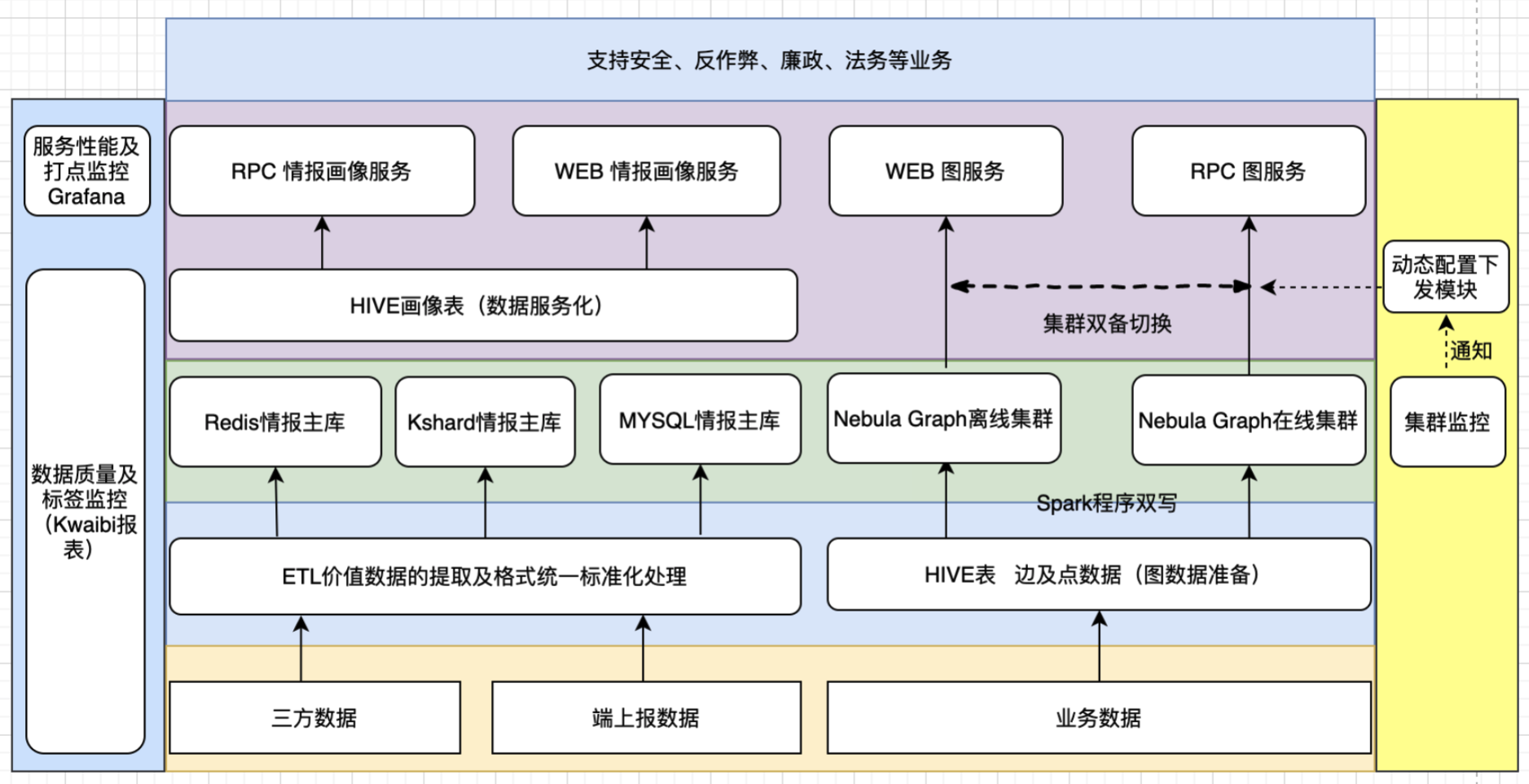
安全情报服务整体架构图
其中,基于图数据库的情报综合查询平台,软件架构如下图所示:
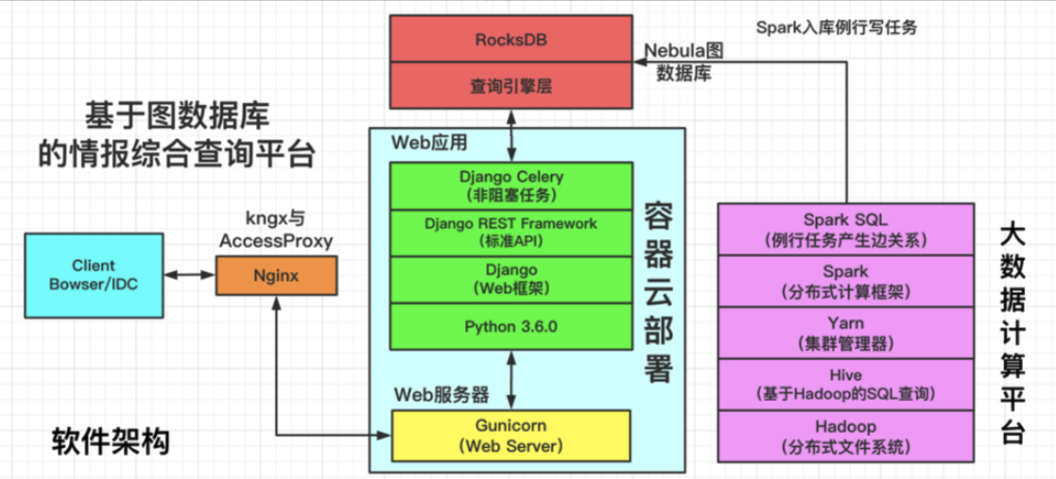
情报综合查询平台软件架构图
注:AccessProxy 支持办公网到 IDC 的访问,kngx 支持 IDC 内的直接调用
4.1 离线数据写入优化
针对所构建的关联关系数据,每天更新的量在数十亿级别,如何保证这数十亿级别的数据能在小时级内写入、感知数据异常且不丢失数据,这也是一项非常有挑战性的工作。
对这部分的优化主要是:失败重试、脏数据发现及导入失败报警策略。
数据导入过程中会由于脏数据、服务端抖动、数据库进程挂掉、写入太快等各种因素导致写 batch 数据失败,我们通过用同步 client API 、多层级的重试机制及失败退出策略,解决了由于服务端抖动重启等情况造成的写失败或写 batch 不完全成功等问题。
4.2 双集群 HA 保证与切换机制
在图数据库部分,快手部署了在线与离线两套图数据库集群,两个集群的数据采用同步双写,在线集群承担在线 RPC 类的服务,离线集群承担 CASE 分析及 WEB 查询的服务,这两个集群互不影响。
同时集群的状态监控与动态配置下发模块是打通的,当某一个集群出现慢查询或发生故障时,通过动态配置下发模块来进行自动切换,做到上层业务无感知。
4.3 集群稳定性建设
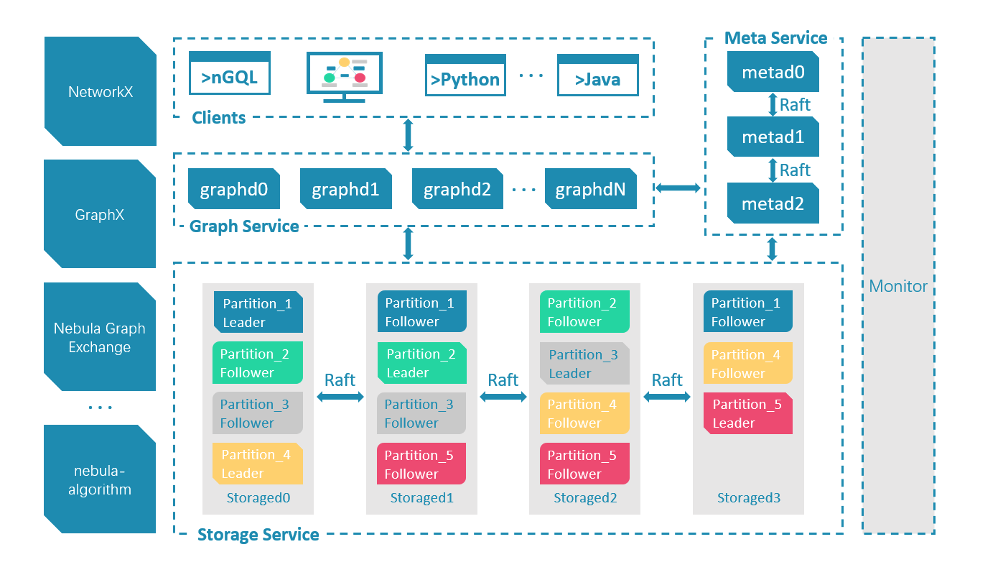
数据架构团队对开源版本的 Nebula Graph 进行了整体的调研、维护与改进。
Nebula 的集群采用计算存储分离的模式,从整体架构看,分为 Meta,Graph,Storage 三个角色,分别负责元数据管理,计算和存储:
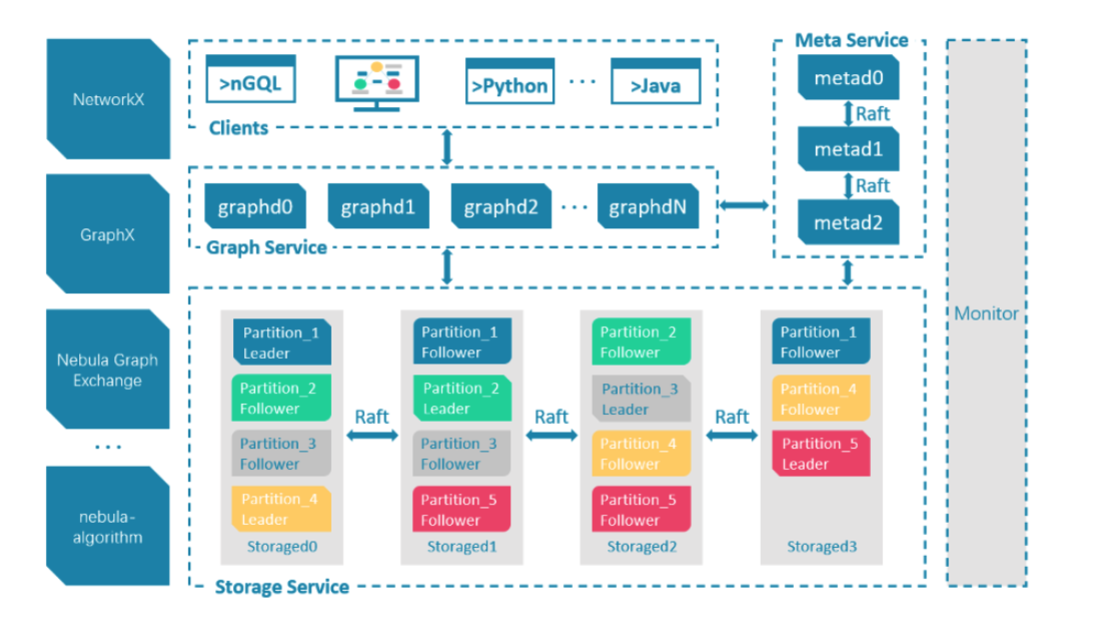
Nebula 整体架构图
Nebula 的存储层作为图数据库引擎的底座,支持多种存储类型,我们使用 Nebula 时选择了经典模式,即用经典的 C++ 实现的 RocksdDB 作为底层 KV 存储,并利用 Raft 算法解决一致性的问题,使整个集群支持水平动态扩容。
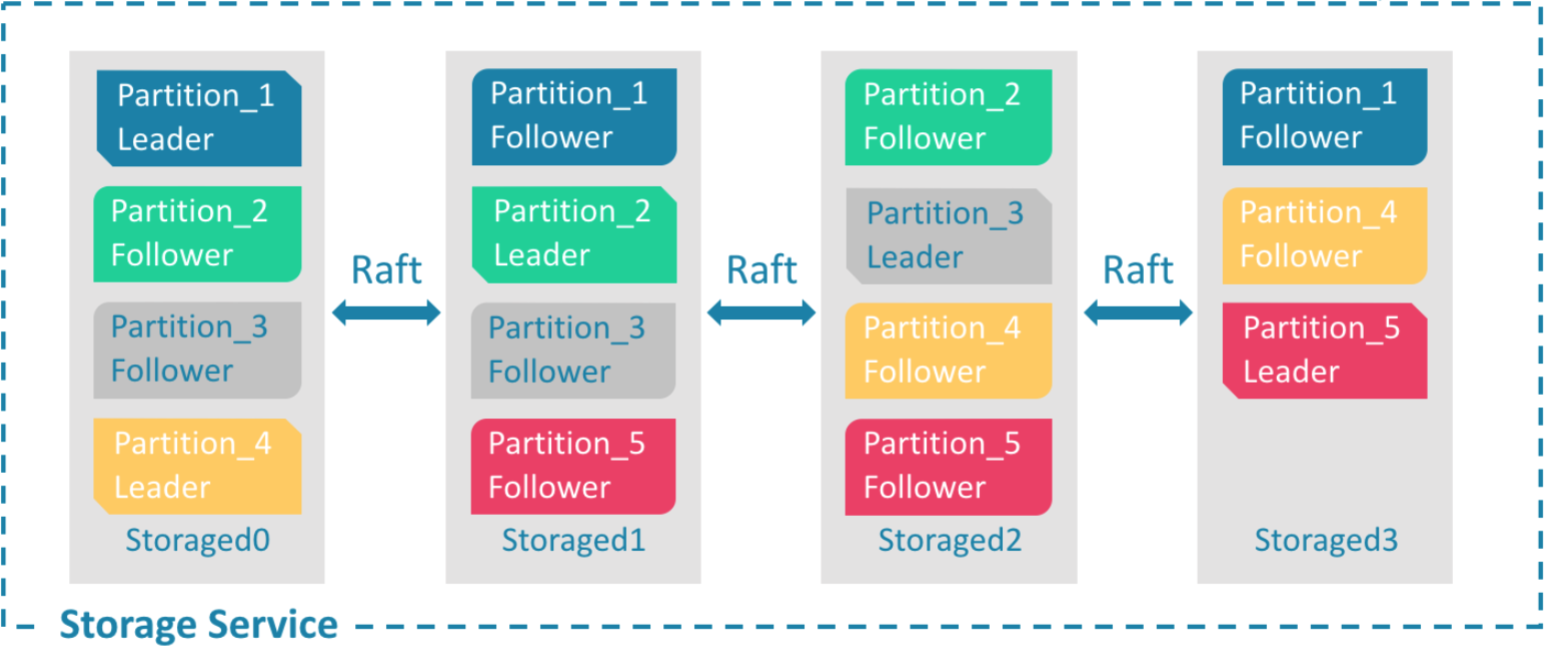
存储层架构图
我们对存储层进行了充分的测试、代码改进与参数优化。其中包括:优化 Raft 心跳逻辑、改进 leader 选举和 log offset 的逻辑以及对 Raft 参数进行调优等,来提升单集群的故障恢复时间;再结合客户端重试机制的优化,使得 Nebula 引擎在用户体验上从最初的故障直接掉线改善为故障毫秒级恢复。
在监控报警体系上,我们构建了对集群多个层面的监控,其整体监控架构如下图所示:
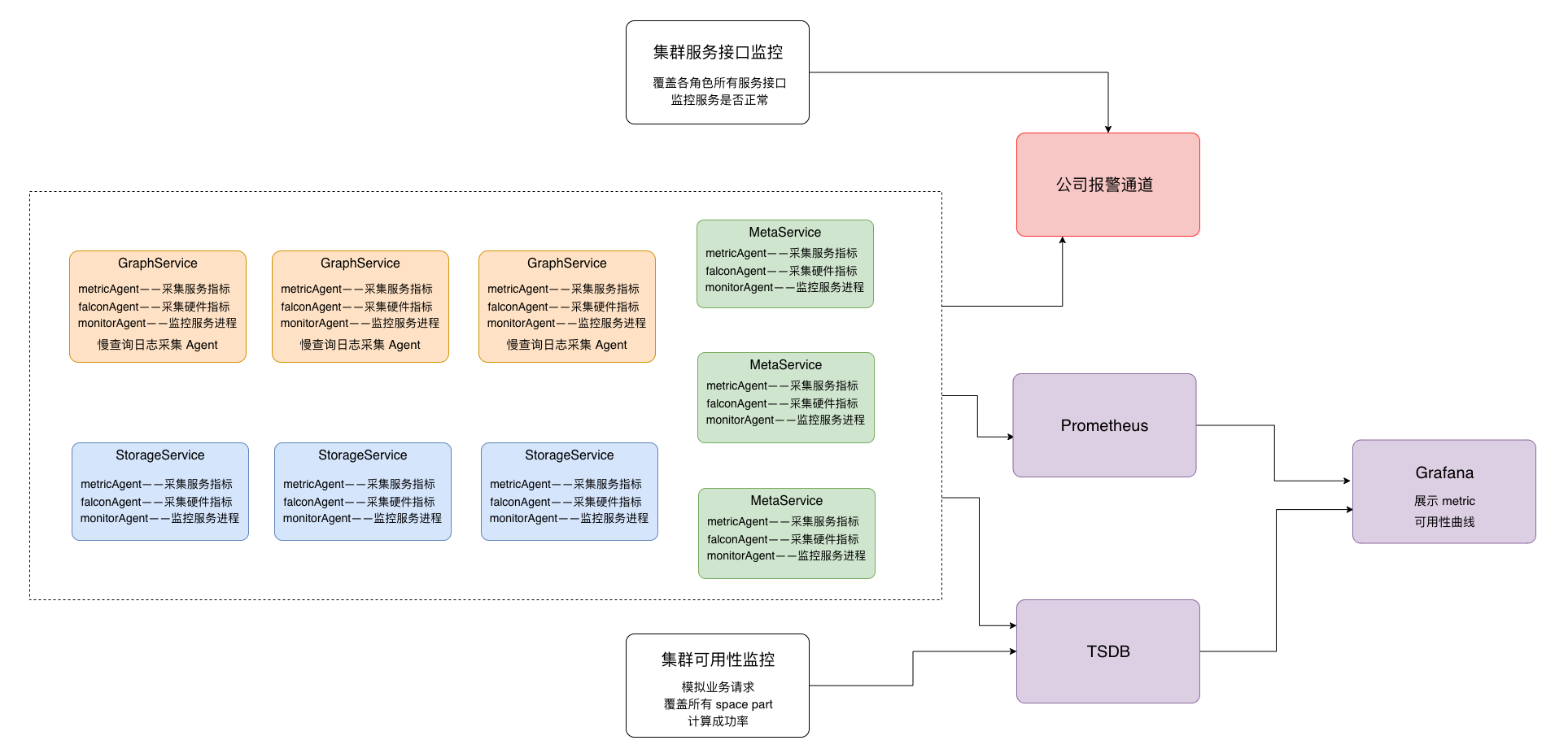
集群监控架构图
包括如下几个方面:
- 机器硬件层面 cpu busy 、磁盘 util 、内存、网络等
- 集群每个角色 meta 、storage 、graph 服务接口监控、partition leader 上线状态及分布的监控
- 从用户角度对集群整体可用性的评估监控
- 集群各角色 meta 、storage 、rocksdb 、graph 的 metric 采集监控
- 慢查询监控
4.4 对超级节点查询的优化
由于现实图网络结构中点的出度往往符合幂律分布特征,图遍历遇到超级点(出度百万 /千万)将导致数据库层面明显的慢查询,如何保证在线服务查询耗时的平稳性,避免极端耗时的发生是我们需要解决的问题。
图遍历超级点问题在工程上的解决思路是:在业务可接受的前提下缩小查询规模。具体方法有:
- 查询中做符合条件的 limit 截断
- 查询按一定比例进行边采样
下面分别描述具体的优化策略:
4.4.1 limit 截断优化
[前提条件]
业务层面可接受每一跳做 limit 截断,例如如下两个查询:
# 最终做 limit 截断
go from hash('x.x.x.x') over GID_IP REVERSELY where (GID_IP.update_time >= xxx and GID_IP.create_time <= xxx) yield GID_IP.create_time as create_time, GID_IP.update_time as update_time, $^.IP.ip as ip, $$.GID.gid | limit 100
# 在中间查询结果已经做了截断,然后再进行下一步
go from hash('x.x.x.x') over GID_IP REVERSELY where (GID_IP.update_time >= xxx and GID_IP.create_time <= xxx) yield GID_IP._dst as dst | limit 100 | go from $-.dst ..... | limit 100
[优化前]
对第二个查询语句,在优化前,storage 会遍历点的所有出度,graph 层在最终返回 client 前才做 limit n 的截断,这种无法避免大量耗时的操作。
另外 Nebula 虽然支持 storage 配置集群(进程)级别参数max_edge_returned_per_vertex(每个 vertex 扫描最大出度),但无法满足查询语句级别灵活指定 limit 并且对于多跳多点出度查询也无法做到语句级别精确限制。
[优化思路]
一跳 go 遍历查询分两步:
- step1:扫描 srcVertex 所有出度 destVertex (同时获取边的属性)
- step2:获取所有 destVertex 的属性 value
那么 go 多跳遍历中每跳的执行分两种情况:
- case 1:只执行 step1 扫边出度
- case 2:执行 step1 + step2
而 step2 是耗时大头(查每个 destVertex 属性即一次 rocksdb iterator,不命中 cache 情况下耗时 500us ),对于出度大的点将「 limit 截断」提前到 step2 之前是关键,另外 limit 能下推到 step1 storage 扫边出度阶段对于超级点也有较大的收益。
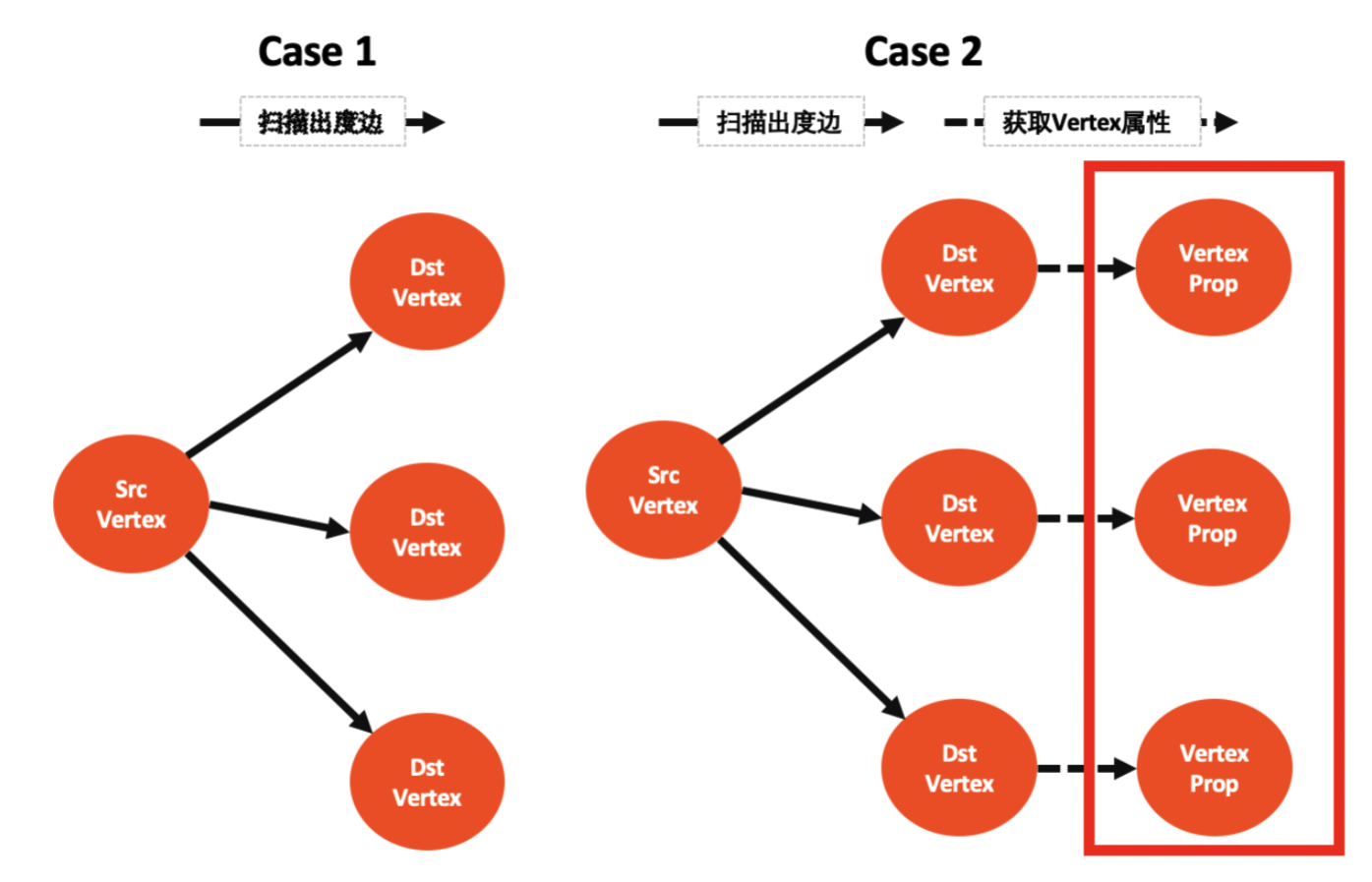
这里我们总结下什么条件下能执行「 limit 截断优化」及其收益:
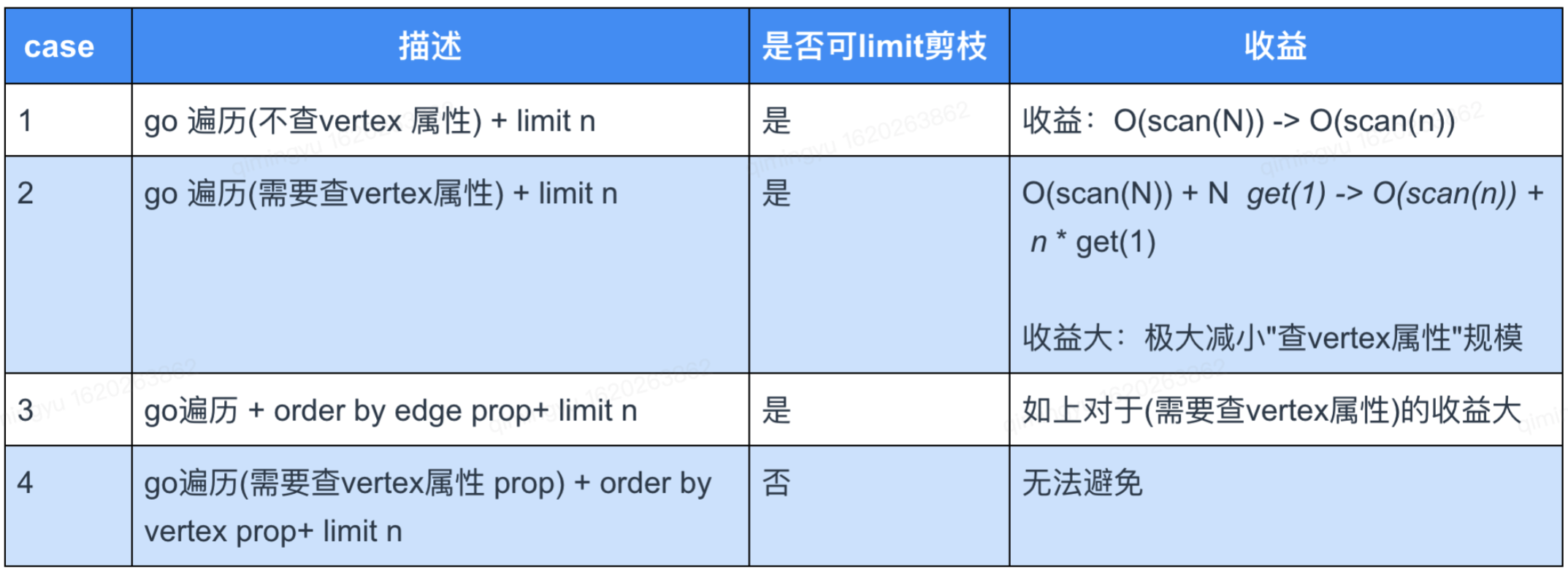
表注释: N 表示 vertex 出度,n 表示 limit n,scan 表示扫边出度消耗,get 表示获取 vertex 属性的消耗
[测试效果]
对于以上 case1 和 case2 可执行「 limit 截断优化」且收益明显,其中安全业务查询属于 case2,以下是在 3 台机器集群,单机单盘 900 GB 数据存储量上针对 case2 limit 100 做的测试结果(不命中 rocksdb cache 的条件):
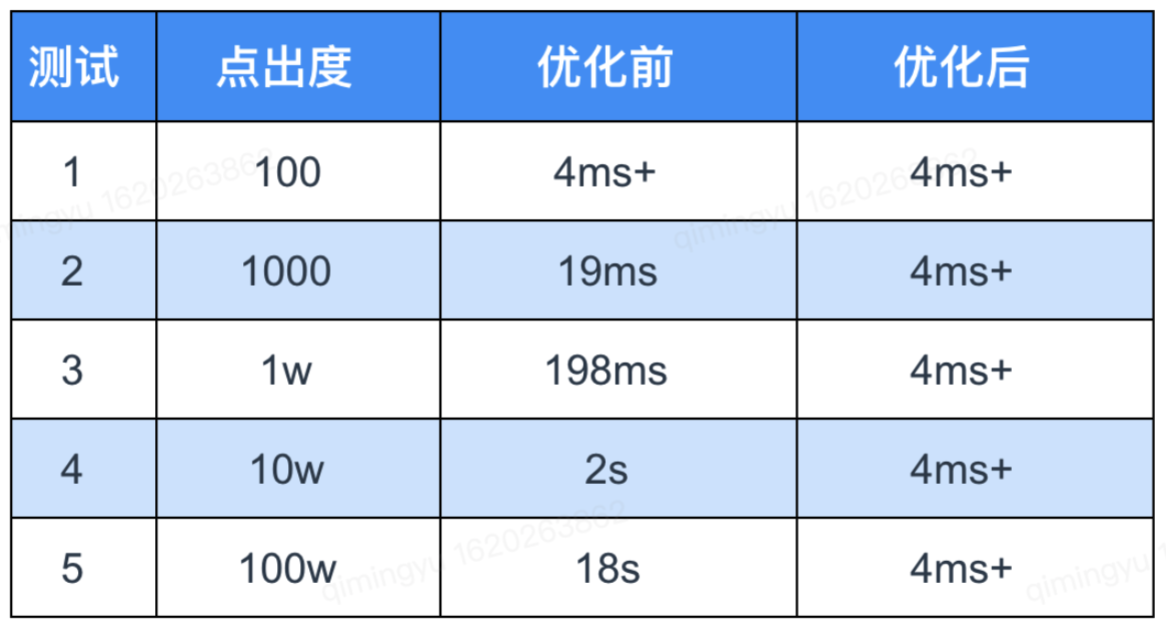
以上测试结果表明,经过我们的优化后,在图超级点查询耗时上,取得了非常优异的表现。
4.4.2 边采样优化
针对不能简单做「 limit 截断优化」的场景,我们可以采取「边采样优化」的方式来解决。在 Nebula 社区原生支持的“storage 进程级别可配置每个 vertex 最大返回出度边和开启边采样功能”基础上,我们优化后,可以进一步支持如下功能:
- storage 开启采样功能后,可支持配置扫
max_iter_edge_for_sample数量的边而非扫所有边(默认) - graph 支持
go每跳出度采样功能 - storage 和 graph 的“采样是否开启
enable_reservoir_sampling”和“每个 vertex 最大返回出度max_edge_returned_per_vertex”都支持 session 级别参数可配
通过以上功能的支持,业务可以更灵活地调整查询采样比例,控制遍历查询规模,以达到在线服务的平滑性。
4.5 查询客户端的改造与优化
开源的 Nebula Graph 有自己的一套客户端,而如何将这套客户端与快手的工程相结合,这里我们也做了一些相应的改造与优化。主要解决了下面两个问题:
- 连接池化:Nebula Graph 官方客户端提供的底层接口,每次查询都需要建立连接初始化、执行查询、关闭连接这些步骤,在高频查询场景中频繁创建、关闭连接极大地影响着系统的性能与稳定性。在实践中,通过连接池化技术对官方客户端进行二次封装,并对连接生命周期的各个阶段进行监控,实现了连接的复用和共享,提升了业务稳定性。
- 自动故障切换:通过对连接建立、初始化、查询、销毁各个阶段的异常监控和定期探活,实现了数据库集群中的故障节点的实时发现和自动剔除,如果整个集群不可用,则能秒级迁移至备用集群,降低了集群故障对在线业务可用性造成的潜在影响。
4.6 查询结果的可视化及下载
针对固定关系的查询(写死 nGQL ),前端根据返回结果,进行定制化的图形界面展示,如下图所示:
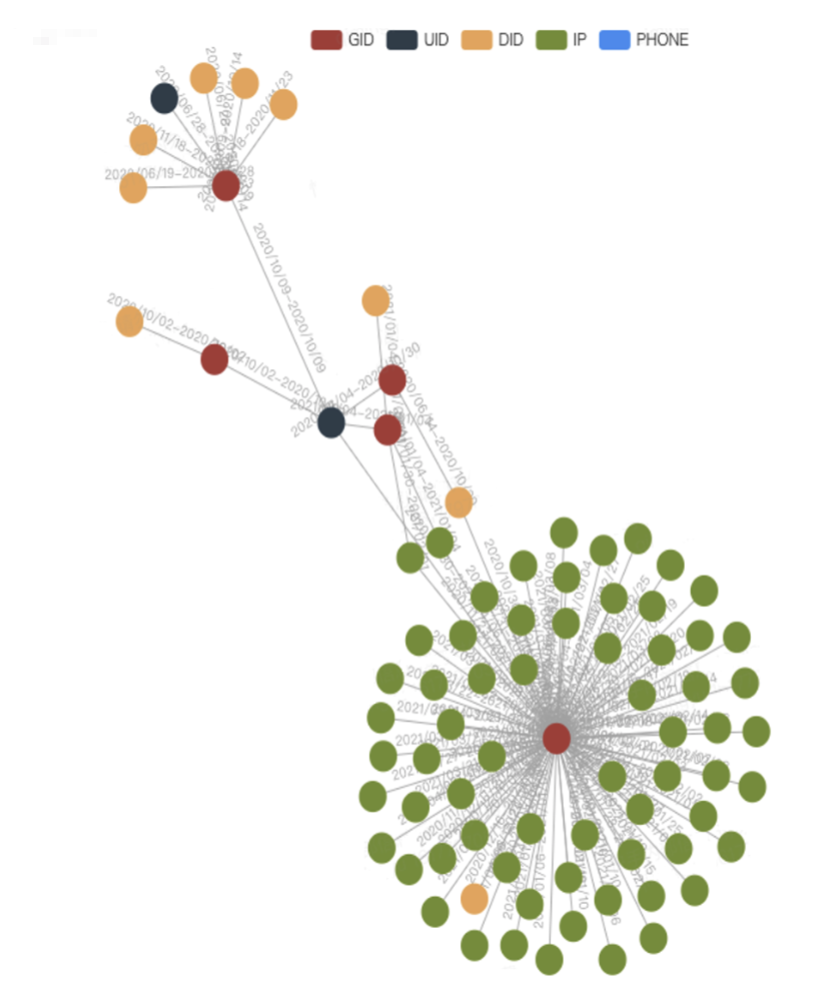
这里前端采用ECharts的关系图,在前端的图结构数据加载及展示这里也做了一些优化。
问题一:关系图需要能展示每个节点的详情信息,而 ECharts 提供的图里只能做简单的 value 值的展示。
解决方案:在原代码上进行改造,每个节点添加点击事件,弹出模态框展示更多的详情信息。
问题二:关系图在点击事件触发后,图会有较长时间的转动,无法辨认点击了哪个节点。
解决方案:获取初次渲染图形时每个节点的窗口位置,在点击事件触发后,给每个节点位置固定下来。
问题三:当图的节点众多时候,关系图展示的比较拥挤。
解决方案:开启鼠标缩放和评议漫游功能。
针对灵活关系的查询(灵活 nGQL ),根据部署的Nebula Graph Studio进行可视化的呈现,如下图所示:
五. 图数据库在安全情报上的实践
基于以上图数据库的结构与优化,我们提供了 Web 查询和 RPC 查询两种接入方式,主要支持了快手的如下业务:
- 支持快手安全的溯源、线下打击与黑灰产分析
- 支持业务安全的风控与反作弊
例如,群控设备与正常设备在图数据上的表现存在明显区别:
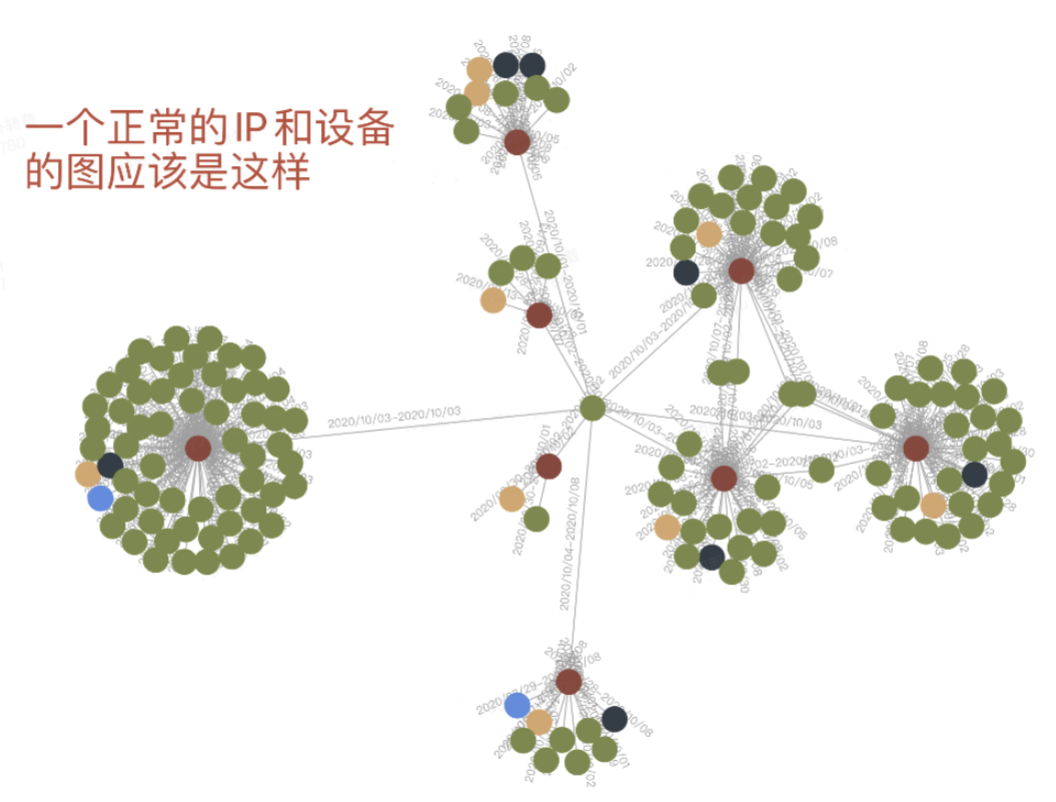
对于群控设备的识别:
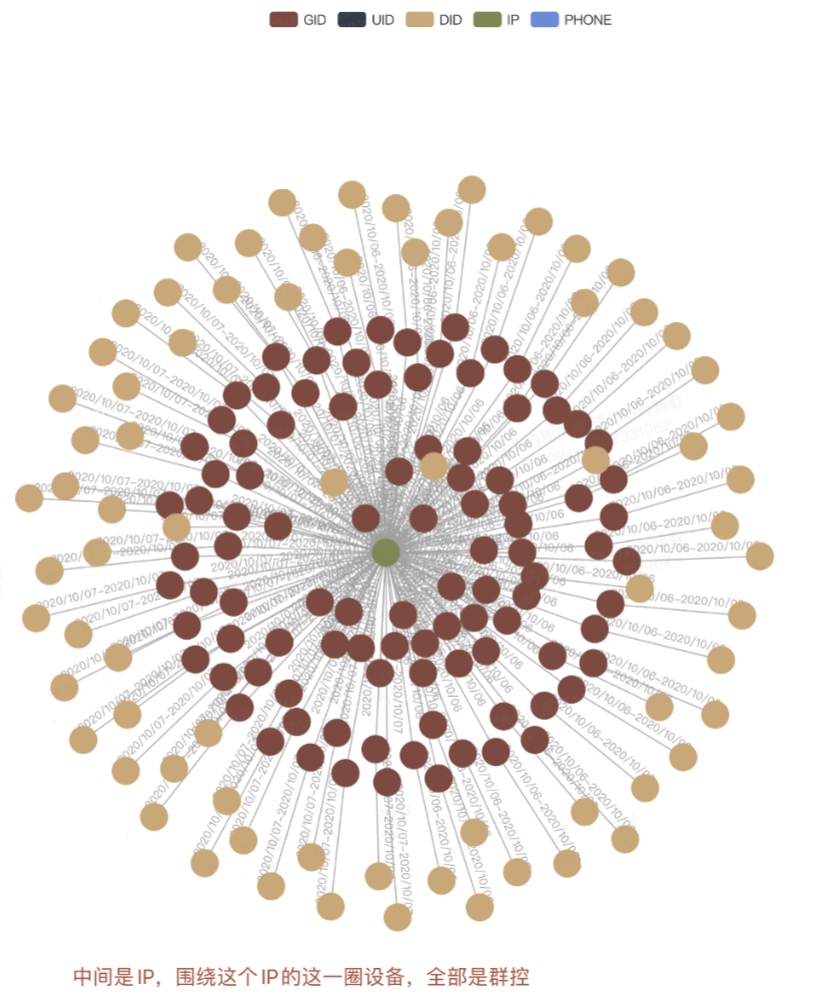
六. 总结与展望
- 稳定性建设:集群 HA 能力实现跨 AZ 集群的实时同步、访问自动切换,以保障 99.99 的 SLA
- 性能提升:考虑改造 RPC 、AEP 新硬件的存储方案、优化查询执行计划
- 图计算平台与图查询打通:建设图计算 /图学习 /图查询的一体化平台
- 实时判定:实时关系的写入及实时风险的综合判定
七. 致谢
感谢开源社区Nebula Graph对快手的支持。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebulae 名片,Nebula 小助手会拉你进群~~
推荐阅读
 |
1
Livid MOD PRO 这篇推广软文已经从 /go/programmer 移动到 /go/promotions
请阅读 V2EX 的节点使用规则: https://www.v2ex.com/help/node 目前你们的账号上会收到 -8 的降权。如果你们接下来愿意尊重规则,那么降权可以取消。 |
 |
2
coderflying 2021-05-18 18:47:55 +08:00
晚些尝试一下
|
 |
3
NebulaGraph OP @Livid 嗯,的确是我选这个节点之前我没仔细研究过这个节点的内容。我看了下程序员节点的东西大多是技术讨论而非技术分享,是我理解错误了。我以后相关的内容会放在推广节点的。
|
|
4
NebulaGraph OP @Livid 其实我有一个困惑点,像是这种数据库类的技术分享,除了发在推广节点之外,我可以去掉文末的推广信息,发在 [数据库] 分类之下吗?
|