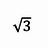比如《字符编码笔记: ASCII , Unicode 和 UTF-8 》 是阮老师 10 年前写的一篇关于字符编码的科普文章,现在用 Google 搜关键字该文章依然名列前茅,可见他的文章有多大影响力,但里面的内容是否正确是值得商榷的事。
中文维基百科对 Unicode 的解释也是让人一头雾水,摸不着头脑。看看阮老师怎么说:
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode ,就像它的名字都表示的,这是一种所有符号的编码。
这句话读起来很拗口,有三个地方出现了「编码」二字。不知阮老师对「编码」的理解是什么?但可以肯定的是这三个「编码」在这句话里面不是同一个意思。
「编码」作动词使用时就是把一个字符(严格一点说是字符在字符集中的编号 code point )转换成一个字节序列,以便在网络传输或者存储到文本中。比如「好」在 Unicode 中的编号是 U+597d ,经过 UTF-8 编码后会转换成二进制序列是 '\xe5\xa5\xbd' 。作为名词使用时,就是指一种具体的编码实现方式,比如 ASCII 编码, GBK 编码, UTF-8 编码
其实 Unicode 是一个囊括了世界上所有字符的字符集,其中每一个字符都对应有唯一的编码值( code point ),然而它并不是一种什么编码格式,仅仅是字符集而已。 Unicode 字符要存储要传输怎么办,它不管,可以用 UTF-8 、 UTF-16 。
再来看阮老师说 Unicode 的第二个问题:
第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是 0 ,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
Unicode 并没有统一规定每个符号用三个或者四个字节表示。 Unicode 只规定了每个字符对应到唯一的代码值( code point ),代码值 从 0000 ~ 10FFFF 共 1114112 个值 ,真正存储的时候需要多少个字节是由具体的编码格式决定的。比如:字符 「 A 」用 UTF-8 的格式编码来存储就只占用 1 个字节,用 UTF-16 就占用 2 个字节,而用 UTF-32 存储就占用 4 个字节。
再看来看这张图:

阮老师对 Unicode 编码的解释是:
Unicode 编码指的是 UCS-2 编码方式,即直接用两个字节存入字符的 Unicode 码。这个选项用的 little endian 格式。
UCS-2 是什么鬼, UCS-2 是使用两个定长的字节来表示一个字符,而 UTF-16 是使用两个变长的字节,遇到两个字节没法表示时,会用 4 个字节来表示,因此 UTF-16 可以看作是在 UCS-2 的基础上扩展而来的。而 UTF-32 与 USC-4 是完全等价的。
之所以在 Windows 下有 Unicode 编码这样一种说法,其实是 Windows 的一种错误表示方法,它真正的编码类型是 UTF-16LE 编码。
他又说:
Unicode 规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"( ZERO WIDTH NO-BREAK SPACE ),用 FEFF 表示。这正好是两个字节,而且 FF 比 FE 大 1 。
如果一个文本文件的头两个字节是 FE FF ,就表示该文件采用大头方式;如果头两个字节是 FF FE ,就表示该文件采用小头方式