
简单试了下天气卡片,中文英文都试了,太简陋了:
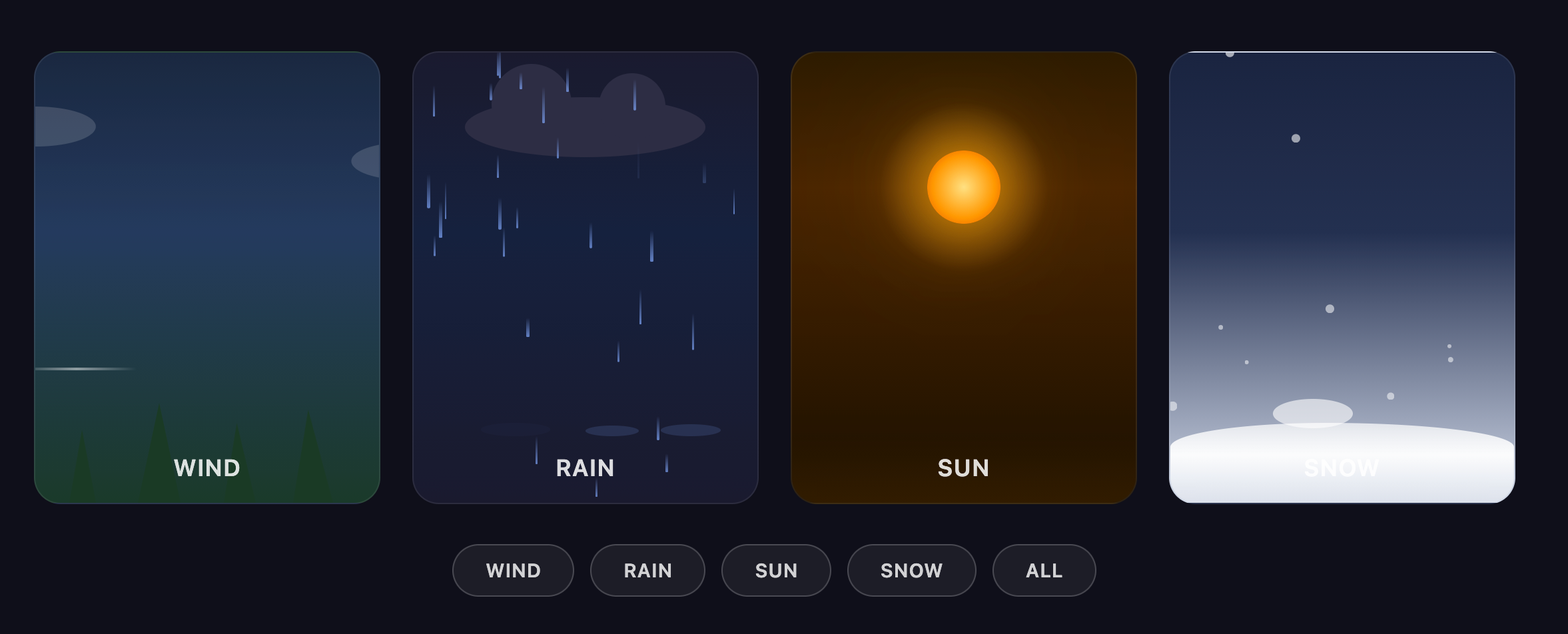
中文:
创建一个包含 CSS 和 JavaScript 的单一 HTML 文件,用于生成动画天气卡片。卡片应该通过不同的动画直观地表示以下天气状况:
风:(例如,移动的云朵、摇摆的树木或风线)
雨:(例如,下落的雨滴、形成的水坑)
阳光:(例如,闪耀的光线、明亮的背景)
雪:(例如,下落的雪花、积累的雪)
所有天气卡片应并排显示,卡片应该有深色背景。
在这个单一文件中提供所有 HTML 、CSS 和 JavaScript 代码。JavaScript 应该包含一种切换不同天气状况的方式(例如,一个函数或一组按钮)以展示每种天气的动画效果。
英文:
Create a single HTML file containing CSS and JavaScript to generate an animated weather card. The card should visually represent the following weather conditions with distinct animations: Wind: (e.g., moving clouds, swaying trees, or wind lines) Rain: (e.g., falling raindrops, puddles forming) Sun: (e.g., shining rays, bright background) Snow: (e.g., falling snowflakes, snow accumulating) Show all the weather card side by side The card should have a dark background. Provide all the HTML, CSS, and JavaScript code within this single file. The JavaScript should include a way to switch between the different weather conditions (e.g., a function or a set of buttons) to demonstrate the animations for each.





















