
这是一个创建于 3284 天前的主题,其中的信息可能已经有所发展或是发生改变。
URL2io.com — 提供简单、强大的网页正文提取服务
今天给大家分享的是一个网页正文提取服务 URL2Article ,主页地址:http://www.url2io.com
URL2Article 服务提供 RESTful API 接口,用来提取并解析网页中的正文区域,实现网页正文提取、标题提取、发布日期提取、下一页链接提取等。
功能列表
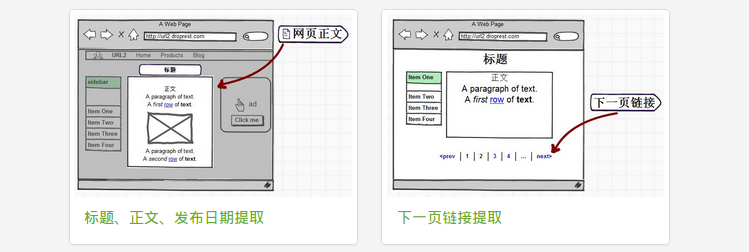
- 标题识别:
不仅仅是简单地提取 title 标签,而是智能识别网页正文的标题。
- 正文识别:
提取的内容将不含有任何广告、导航和其他非正文内容。网页正文中的所有链接、图片和其他媒体将予以保留。
- 发布日期识别:
智能识别文章的发布日期。
- 下一页链接识别:
智能识别当前网页的下一页链接。因为一篇完整的文章会被分成多个页面,所以这个功能会非常有用。
Demo
demo 地址:点这测试效果。
API 使用文档
可以查看相关文档 (URL2Article API doc) 来了解如何使用。
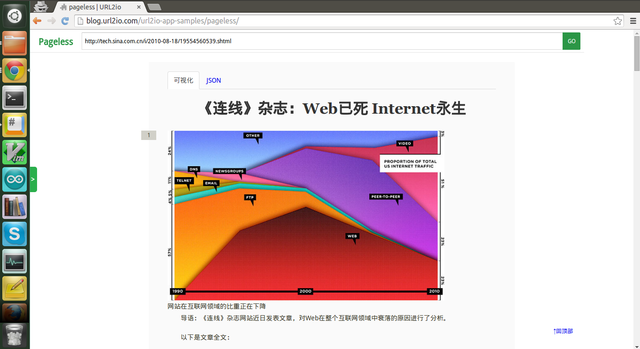
示例应用
为了让大家近一步了解这项服务,我们写了一个教学示例 Pageless, 它使用 URL2Article API 来提取网页正文,并自动将被分成多页的文章合并成一页。
演示地址, 代码在 Github: url2io-app-samples
Feedback
That's all. 希望有兴趣的童鞋可以试用一下,然后给点反馈(使用中出现的问题、会用来开发什么、意见和建议等都可以)。 欢迎留言讨论,或者 url2#sina.com ,或者 QQ 用户群: 341180183
第 1 条附言 · 2016-10-27 11:45:23 +08:00
近期的一些更新:(2016-10-02 ~2016-10-27)
根据大家的反馈和讨论做了大量更新,包括算法优化、新特性支持、其他更新等。
优化 (Breaking Changes): —— URL2Article
- 针对正文上卷问题做了优化
- 运行速度优化
新特性 (New Features):—— URL2Article
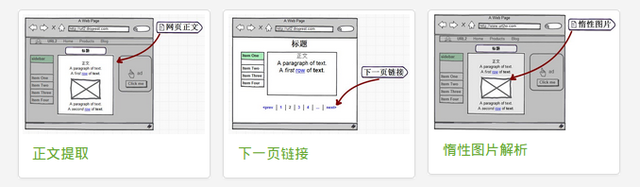
- 对于
<img>标签会保留全部属性,方便之后的处理。 - 支持惰性图片解析,智能识别正文中的惰性图片,并自动将图片地址解析为真实地址。
现有功能列表:
其他更新 (Other Changes):
- 在文档中心添加了 Quickstart ,提供多种编程语言(Python、NodeJS、PHP、Ruby ...)和工具(Curl ...)的使用示例,方便大家快速(约 20 秒)上手。
- 新增 PHP SDK:url2io-phpsdk ,由 @ety001 提供,十分感谢!
- 对于用 js 渲染内容的动态页面,在 UA 中使用兼容搜索引擎蜘蛛的特征串可以抓取到网页的静态版(感谢 @blueset 提供的思路),不过此方法的稳定性还在测试中,所以此次更新暂时还不能提供 -_-
That‘s all. 非常感谢大家的反馈和讨论,URL2io 的成长离不开热心朋友的关注与支持。 欢迎继续留言讨论,或者 url2#sina.com ,或者 QQ 用户群: 341180183,或者 Github Issues,或者关注微薄 @url2io
第 2 条附言 · 2018-01-28 11:43:10 +08:00
URL2io Enterprise 服务发布
URL2io Enterprise 是 URL2io 的本地部署版本,您可以在自己的环境中进行安装部署和管理。
目前包含了 URL2Article 服务(用来提取并解析网页中的正文区域,实现网页正文提取、标题提取、下一页链接提取等。)



 |
1
geeglo 2016-09-30 11:37:47 +08:00 via iPhone
我反正是没这需求,自己解析也挺方便的
|
 |
3
DoraJDJ 2016-09-30 11:52:26 +08:00
用自己的 blog 试了一下,好像连头像都不小心给抓到了 23333
 |
 |
4
jy02201949 2016-09-30 11:55:37 +08:00
不错不错,想当年刀耕火种的年代,用雅虎的 pipe ,之后是自己写代码,如今已经开始自动化了
|
 |
6
tscat 2016-09-30 12:35:05 +08:00 via iPhone
收藏一下,午休后看看。希望比有道的好用
|
 |
7
URL2io OP @jy02201949 看来是老司机了,自动化之后能做的事就有意思了,比如 URL2Article 与 pipe 的结合
|
 |
8
wuyadong 2016-09-30 12:47:26 +08:00
下一页连接,是怎样识别的呀,能否大致告知一下。谢谢
|
 |
10
doubleflower 2016-09-30 13:05:32 +08:00
这个攫取服务器是在国内还是国外的?
|
|
11
URL2io OP @wuyadong 大致的假设是本页链接与下一页链接的网址不会相差太大,应该有一个特定的模式。通过收集大量网站的下一页链接,做特征工程,再通过机器学习训练和预测下一页链接。只能讲这么多了 -_-
如果有相关需求还是推荐使用我们的产品,肯定比自己写的好用 ^_^ |
|
12
doubleflower 2016-09-30 13:08:19 +08:00
|
|
13
URL2io OP @doubleflower 知乎专栏这种通过 ajax 加载内容的网页暂时还不支持,要渲染 js 的开销太大了。
它的[接口]( https://zhuanlan.zhihu.com/api/posts/22597353)还是挺好找的,不过现在还没有找到一种高效、普适的方法就没有处理这种情况。 |
 |
14
iyaozhen 2016-09-30 13:20:47 +08:00 挺不错的。赞
|
|
15
doubleflower 2016-09-30 13:20:56 +08:00
@URL2io 先用普通方式抓,发现没内容就用浏览器方式。
|
|
16
URL2io OP @doubleflower 用浏览器方式是指加上 User-Agent 吗?也不行啊。它的内容是靠 js 加载的,也就是说如果浏览器禁用了 js ,那直接用浏览器访问都没有内容。
Google 的爬虫可以收录 JS 和 CSS 内容,用的方法好像也不是全部渲染,不知道怎么实现的...... |
|
17
doubleflower 2016-09-30 13:51:52 +08:00 @URL2io 用这种 http://phantomjs.org/ 现在的很多网页爬虫就是这么搞的。
|
|
18
URL2io OP @doubleflower 感谢感谢
|
 |
19
leilux 2016-09-30 15:33:41 +08:00
提取结果还是挺准的,赞一个
|
 |
20
Aether 2016-09-30 15:35:11 +08:00
 抓 V2EX 的时候…… |
 |
21
xxm459259 2016-09-30 15:39:56 +08:00
是在 readability 基础上做的么?
|
 |
22
xvx 2016-09-30 15:50:01 +08:00 我搜索了一下,发现有个效果比 LZ 的要好……不过不是开源的。 LZ 研究下。
http://www.weixinxi.wang/open/extract.html |

|
24
URL2io OP |
|
25
URL2io OP @xvx 这个我在开发时也搜到过,也一直作为比较的对象。效果上来说他这个倾向于于获取更少的正文,所以看上去会简洁一点,不过对于一些奇怪的页面效果就不太好。我这个倾向于获取更多的正文,所以在头部偶尔会将多余的内容卷进来,不过普适性更好,遇到很奇怪的页面都可以提取。其实不同的人对一个页面正文的部分的定义是不同的,要在简洁与普适这两者之间进行权衡。
|
|
26
URL2io OP @gujiaxi Pageless 的吗?
将书签的地址改为: <pre>javascript:location.href = 'http://blog.url2io.com/url2io-app-samples/pageless/?url='+encodeURIComponent(location.href);</pre> 不过 Pageless 用的是演示用的 API 是有频率限制的,可以根据 Pageless 的源码再结合正式的 API 搭建一个。 |
|
27
Aether 2016-09-30 17:53:49 +08:00 @URL2io 可能要针对主要网站都做一遍优化?这可是苦力活儿,但也是值钱的活儿;但是你可以列一堆 logo ,表示「这些网站已特别优化」,让用户放心使用。
|
 |
28
techmoe 2016-09-30 18:09:15 +08:00 via Android
做这个的思路是什么?计算页面占比最大的 div ?
|
|
30
URL2io OP @techmoe 思路点抓得很好,不过页面占比只是众多特征中的一个。如果有相关需求还是推荐使用我们的产品,肯定比自己写的好用 ^_^
|
 |
31
designer 2016-09-30 22:26:10 +08:00 支持,是不是有点像 pocket 插件
|
 |
32
missdeer 2016-09-30 22:33:54 +08:00 效果也就一般,比如我一直看的盗版小说页面 http://www.piaotian.net/html/7/7762/5084075.html 页脚都没去掉
|
 |
33
alexapollo 2016-10-01 00:01:55 +08:00 斯坦福前两年有篇论文写的就是这个方法,简单粗暴,但是做起来估计也得有不少 dirty work
|
|
34
xxm459259 2016-10-01 00:10:14 +08:00 @URL2io 之前给团队项目做过一个类似的功能,我开始是在 Readability 基础上改,后来从 evernote 的 clearly 插件源码中又学了一些奇技淫巧。总的感觉 dirty work 比较多,以及很多 tricks …
|
|
35
URL2io OP @designer 对,不同的是,把类似于 pocket 的提取功能作为接口提供给开发者了,这样自己都可以做一个 pocket 了。感谢支持!
|
|
37
URL2io OP |
 |
38
blueset 2016-10-01 11:01:31 +08:00 建议抓取用的 UA 兼容一下其他搜索引擎蜘蛛的特征串(除了 Google )
部分用 JS 渲染内容的站点(比如我的)开启了根据 UA 判断针对 Bot 推送索引用全文的功能。这样提取起来也会方便些。 之所以说除了 Google 是因为 Google 的蜘蛛 Bot 可以解析渲染 JS 。所以很多类似的库就把 Google 排除在外了。 |
 |
40
15015613 2016-10-01 21:02:02 +08:00 |
 |
41
livc 2016-10-01 21:13:21 +08:00
telegram 的正文不知如何提取的
|
|
43
URL2io OP @15015613 贴吧、论坛之类的帖子其实可以理解为一篇文章的评论部分,所以从我们的角度来说这些帖子其实是没有正文的 -_-!
不过这种应该算是更广义的正文了,目前我们还没这个精力去做这方面的研究…… |
 |
44
jqw1992 2016-10-02 10:27:22 +08:00 强大
|
 |
45
iannil 2016-10-02 11:01:38 +08:00 微信公众号文章,图片全丢。
|
 |
46
Warder 2016-10-02 13:32:20 +08:00 嗯,效果还挺不错
|
 |
47
qianddream 2016-10-02 14:26:12 +08:00
@URL2io 知乎这种问答网站如何处理?
|
|
48
URL2io OP @iannil 目前还不支持网页中惰性加载的图片,不过这部分和 URL2Images (开发中) 用到的技术有交叉,所以之后会加上对这个的支持。感谢反馈!
|
|
49
URL2io OP @qianddream 仅从问答上来说,知乎有两类页面:
1. [https://www.zhihu.com/question/49658687]( https://www.zhihu.com/question/49658687) 用来展示提问者的问题,不过同时可包含了许多回答者的解答。形式上可以理解为一篇每个回复都比较长的帖子,正文的概念很弱。结果就是效果不一,无法评判。 2. [https://www.zhihu.com/question/49658687/answer/117123835]( https://www.zhihu.com/question/49658687/answer/117123835) 用来展示回答者对一个问题的解答。形式上可以理解为一篇博客文章,提取这种还是 URL2Article 比较擅长的。 所以,还是看使用者的策略吧,比如:从提问页提取出所有回答的链接,再用 URL2Article 提取出每个回答。 |
 |
50
beidouxun 2016-10-02 16:28:04 +08:00 via Android
我最近对这方面很感兴趣。尤其是如何判断正文部分和发布日期的。我的网站后台必须填写相关规则才能提取。
|
 |
52
xiubin 2016-10-03 08:20:40 +08:00 via iPhone
Mark ,打算写一个 RSS 阅读器,估计用的到。以后会有一直维护,和免费吗?
|
 |
53
20015jjw 2016-10-03 09:12:41 +08:00
希望能 push 到 kindle
|
|
54
URL2io OP @xiubin 请放心会一直维护的。对于免不免费还没考虑过,还早呢,现阶段只想把产品打磨得更好。
|
|
55
URL2io OP @20015jjw Pageless 就是个教学示例而已啊 -_-|| ,不过用我们提供的正文提取 API 开发个 send to kindle 的应用也不难。
|
 |
56
xiaoz 2016-10-04 09:21:20 +08:00 via iPhone 目前已经用接口撸了个小工具,非常感谢楼主,希望继续维护下去。另外贵方服务器是多台吗?会不会出现被屏蔽 ip 的情况。
|
|
57
URL2io OP @xiaoz 感谢使用!会一直做下去的。即使是多台服务器屏蔽 ip 的情况还是会出现,接下去会针对这个可能出现的情况做相应的处理。
|
 |
58
dphdjy 2016-10-05 07:31:02 +08:00 via Android
mark
前年找过类似服务,最后一个基于内容块的分析,还有一个是对不同页面做适配,然而用起来挺麻烦的。。。 看过悦读的源码,有点多就放弃了。。。 等 po 优化完成,再折腾 |
 |
61
v9ox 2016-10-06 06:10:40 +08:00
试了 google 和 t66y 都不行 (还以为能顺手翻墙
|
 |
63
HanSonJ 2016-10-07 13:51:26 +08:00
|
 |
67
Izual_Yang 2016-10-07 17:04:25 +08:00 via Android
@missdeer
有看小说用的油猴子脚本, My Novel Reader |
 |
68
olbb 2016-10-08 11:30:51 +08:00
可以提取分页内容吗
|
|
69
URL2io OP @olbb 可以的,请求时带上 next 参数,在返回的数据中就会包含当前网页的下一页链接(如果有的话)。
* 具体文档可以看 http://www.url2io.com/docs * 具体示例可以看 pageless ,它就利用了这个特性,实现持续地加载分页中的正文内容 其实帖子中都写了的…… -_- |
 |
70
typcn 2016-10-10 08:44:56 +08:00 比起 import 还是差不少。。 JS 翻页识别不到,列表页面第一项被识别成标题,图片 lazyload 识别不到
|
 |
71
ljcarsenal 2016-10-10 09:46:13 +08:00 ARGUMENT DESCRIPTION
error type : "HTTPError" message : "HTTP 599: socket write not completed (_ssl.c:562)" url : "http://taobao.com" code : "599" |
 |
72
tinyproxy 2016-10-10 12:15:10 +08:00 |
|
73
URL2io OP @ljcarsenal 已经解决,感谢反馈!
|
|
74
URL2io OP @tinyproxy 知乎专栏这种通过 ajax 加载内容的网页暂时还不支持,要渲染 js 的开销太大了。 虽然它的接口
https://zhuanlan.zhihu.com/api/posts/21454432 还是挺好找的,不过现在还没有找到一种高效、普适的方法,就没有处理这种情况。 PS :看完你推荐的这个网页,我内心涌起了想要为知乎日报做特殊处理的冲动 -_- |
 |
75
BOYPT 2016-10-10 14:43:36 +08:00 好东西,, mark 一下。
|
 |
76
Yeoman 2016-10-10 16:52:07 +08:00 via Android
提取正文这种需求只有在爬小黄蚊的时候遇到过
|
 |
77
Youen 2016-10-10 17:37:23 +08:00
可以去 1024 撸种子啊~~
|
|
78
URL2io OP @typcn 和 import 没法比啊,它把采集相关的通通都做了 -_- 。而我们只是提供了一个功能,让大家可以集成到自己的软件系统中(或许也可以集成到 import 中)。两者的关系更像是框架与库的关系。
目前有关 js 动态渲染的东西都不支持,不过图片 lazyload 之后会支持的…… 方便贴一下“列表页面第一项被识别成标题”的网址吗?目前在对正文提取做优化,十分需要这种提取效果不好的样本…… |
 |
79
jeremaihloo 2016-10-11 00:07:21 +08:00 |
|
80
URL2io OP @jeremaihloo 恩,速度比较快、准确率也不错。 cx-extractor 使用基于不用解析 dom 解析的行分块 ,这是一大优点。不过因此也带来了一些限制。因为使用行分块,所以提取前要去除 html tag ,这样就只能提取出文字内容了,顶多保留 img 标签作为文字内容也提取出来。另一个就是要对其进行扩展比较难,因为提取其他信息如标题、日期、下一页链接这些还是需要 html tag 的信息的。
|
 |
83
nicoljiang PRO |
|
84
URL2io OP @nicoljiang 可以的啊, blog 是托管在 github 上的,这两天习惯性抽风,要多刷几次 -_-
|
 |
85
ghosrt 2016-10-27 15:52:27 +08:00
随手试了一下 cnBeta 的一个新闻地址,最后的文字广告连接也被识别为正文了……:)
|
|
86
URL2io OP @ghosrt 不做语义分析,要去除文字广告太难了... 如果实现了那可以开个 URL2block 服务了,哈哈
|
 |
87
ldehai 2016-10-30 19:29:55 +08:00
@URL2io http://aventlabs.com/meetcode 这个没抓出来
|
 |
88
soulmine 2016-10-31 11:05:18 +08:00
@URL2io 有几个问题 1.图片都是网络链接 一旦遇上外链失效的图片 那就是无效 2.爬论坛或者贴吧这种 需要的回复之类的文字和图片 而不是仿格式的页面 json 里面还是一堆的 html 标签 这个和没使用有区别么 2333
不过用来抓下一页 时间和标题还是很方便的 希望有答复 |
|
89
URL2io OP @soulmine 感谢使用!
1. 验证外链是否失效不会出现在正文提取阶段,所以对于外链失效就要自己想办法了,毕竟还有 src 在。 2. 这次发布是 URL2Article ,顾名思义适用范围是新闻,博客等有 article 概念的页面。从返回的字段也可以看出是一篇文章或新闻等的相关信息。如果是一个适用于提取论坛或贴吧的服务,那它返回的字段肯定完全不同,比如每条回复的作者、回复时间、回复内容、第几楼、甚至回复的是哪条回复都要提取为相应的字段。当然之后可能会开发适用于论坛类页面的服务。^_^ 3. 关于一堆 html 标签的问题,还是适用范围的问题。 article 类的页面它的布局相对来说是比较稳定的,所以通过一个设计良好的 CSS 可能达到比原页面还好的显示效果,可以看看示例应用 Pageless 的效果。论坛类的布局就太和 7 和 7 混乱了,而且严重依赖原站的 CSS 设计,所以如果不能提取出第 2 条所说的那些字段,要想得到不是仿格式的页面恐怕有点难了。 4. URL2Article 也提供了输出纯文字内容的选项,只不过图片作为 html 标签也会去除。 可能我在帖子的开头没有很清楚地说明适用范围。不过从用户的反馈来看提取论坛类页面的需求也很大啊? |
|
90
URL2io OP @ ldehai 不知道该说什么好……
|
 |
92
zlong 2016-11-19 10:58:18 +08:00
就是不知道这工具有什么用处
|

 |
98
qsnow6 2017-04-24 19:56:17 +08:00
可以直接给爬虫用么?担心会不会爬挂了
|
 |
100
cnfuyu 2017-05-08 16:27:45 +08:00
只有 API 吗?现在本地有一个 G 的数据需要提取正文,也只能用 API 的方式吗😭
|